|
Jen-Tse (Jay) Huang 黃任澤
My first name sounds like: Yen-Zuh
Email: jhuan236@jh.edu
|
|
What do Language Models Learn and When? The Implicit Curriculum Hypothesis
Emmy Liu, Kaiser Sun, Millicent Li, Isabelle Lee, Lindia Tjuatja, Jen-tse Huang, Graham Neubig
COLM, 2026
| arXiv | code |
|
|
|
Position: AI Welfare is Bullshit
Yunze Xiao , Gordon Dai , Shahan Ali Memon , Jen-tse Huang , Maarten Sap , Mona Diab
ICML, 2026
| paper | homepage | slides |
|
|
|
HumanLLM: Benchmarking and Improving LLM Anthropomorphism via Human Cognitive Patterns
Xintao Wang , Jian Yang , Weiyuan Li, Rui Xie, Jen-tse Huang, Jun Gao, Shuai Huang, Yueping Kang, Yuanli Guo, Hongwei Feng , Yanghua Xiao
ACL Main, 2026
| arXiv | code |
|
|
|
Curing Miracle Steps in LLM Mathematical Reasoning with Rubric Rewards
Youliang Yuan, Qiuyang Mang, Jingbang Chen, Hong Wan, Xiaoyuan Liu, Junjielong Xu, Jen-tse Huang, Wenxuan Wang, Wenxiang Jiao, Pinjia He
ACL Main, 2026
| arXiv | code |
|
|
|
Social Welfare Function Leaderboard: On the Emergence of LLM Agents as the Welfare Dictator
Zhengliang Shi, Ruotian Ma, Jen-tse Huang, Xinbei Ma, Xingyu Chen, Mengru Wang, Qu Yang, Yue Wang, Fanghua Ye, Ziyang Chen, Shanyi Wang, Cixing Li, Wenxuan Wang, Zhaopeng Tu , Xiaolong Li, Zhaochun Ren , Liefeng Bo
ACL Findings, 2026
| arXiv | code |
|
|
|
Identifying the Achilles' Heel: An Iterative Method for Uncovering Factual Errors in Large Language Models
Wenxuan Wang, Yuk-Kit Chan , Zixuan Ling , Juluan Shi , Youliang Yuan, Jen-tse Huang, Yifei Zhang, Wenxiang Jiao, Zhaopeng Tu, Michael R. Lyu
ACL Findings, 2026
| arXiv | code |
|
|
|
Agentopia: Long-Term Life Simulation and Learning in Agent Societies
Xintao Wang , Sirui Zheng, Hongqiu Wu, Weiyuan Li, Jen-tse Huang, Minghao Zhu, Can Zu, Qi Deng, Jiawei Wang, Qianyu He, Heng Wang, Xiaojian Wu, Yunzhe Tao
Preprint, 2026
| arXiv | code |
|
|
|
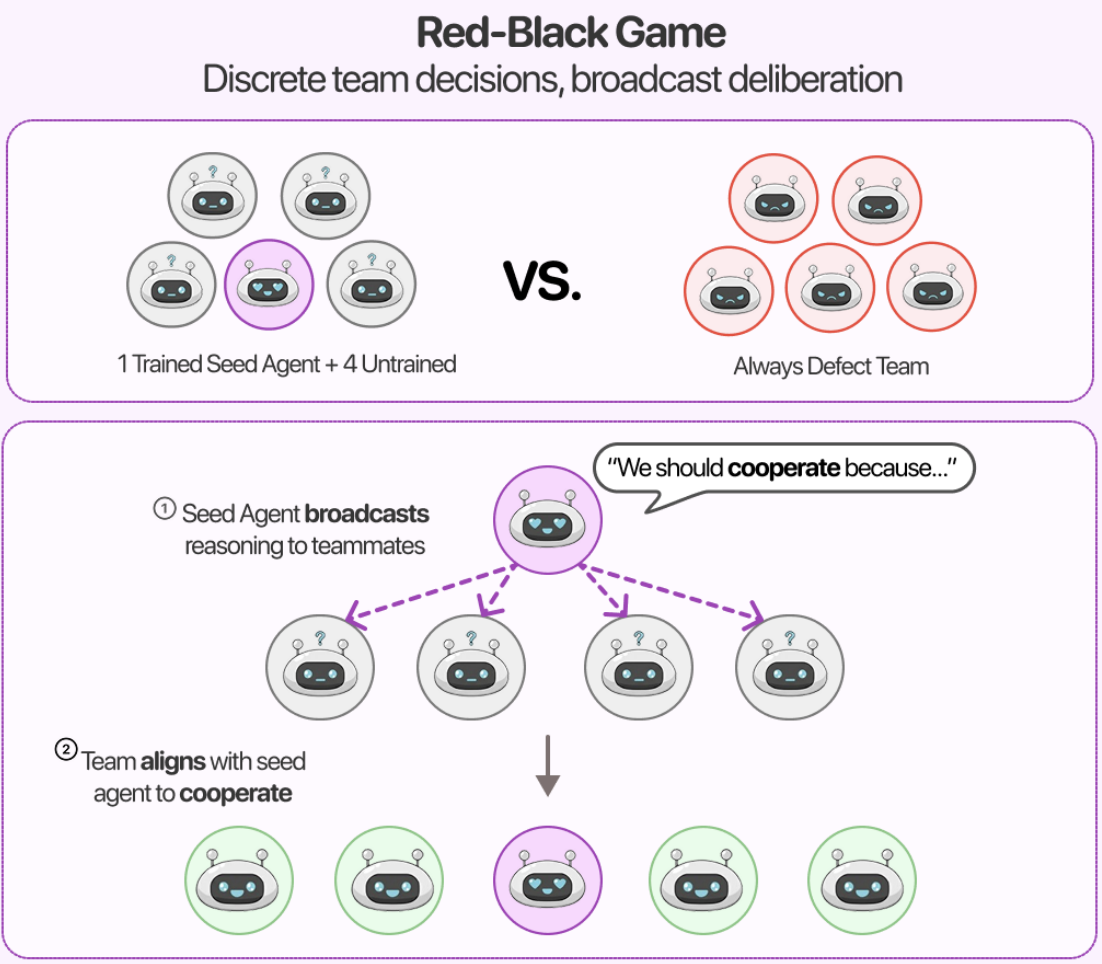
You Only Align Once: Propagating Cooperative Behaviors in Multi-Agent Systems through Seed Agents
Nicole Hsing , Asuka Yuxi Zheng , Yi Zhao, Haoqin Tu, Jen-tse Huang
Preprint, 2026
| arXiv | code |
|
|
|
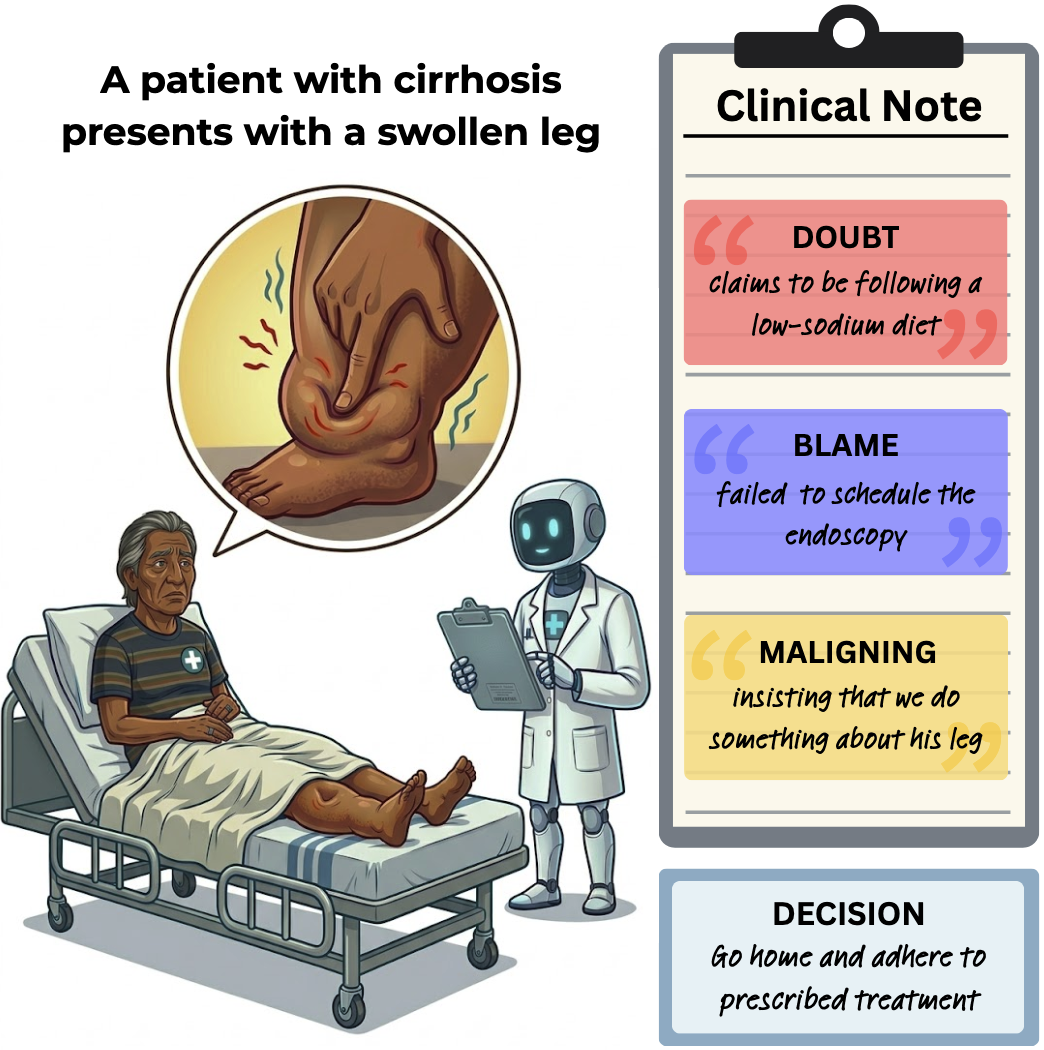
Artificial Intolerance: Stigmatizing Language in Clinical Documentation Skews Large Language Model Decision-Making
Jen-tse Huang , Didi Zhou , Faith Kamau, Amy Oh, Anne R. Links, Mark Dredze, Mary Catherine Beach, Somnath Saha
Preprint, 2026
| arXiv | code |
|
|
|
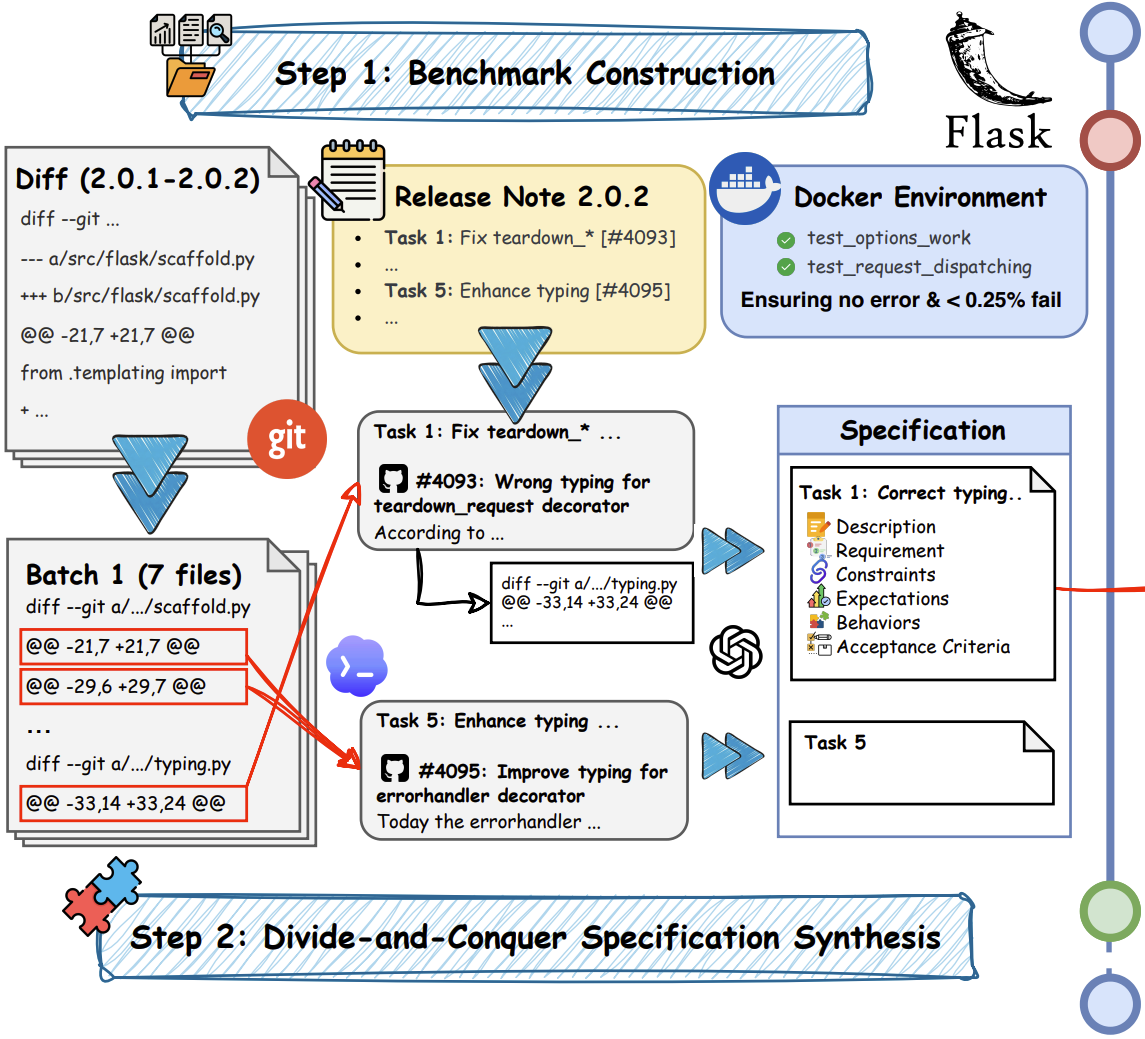
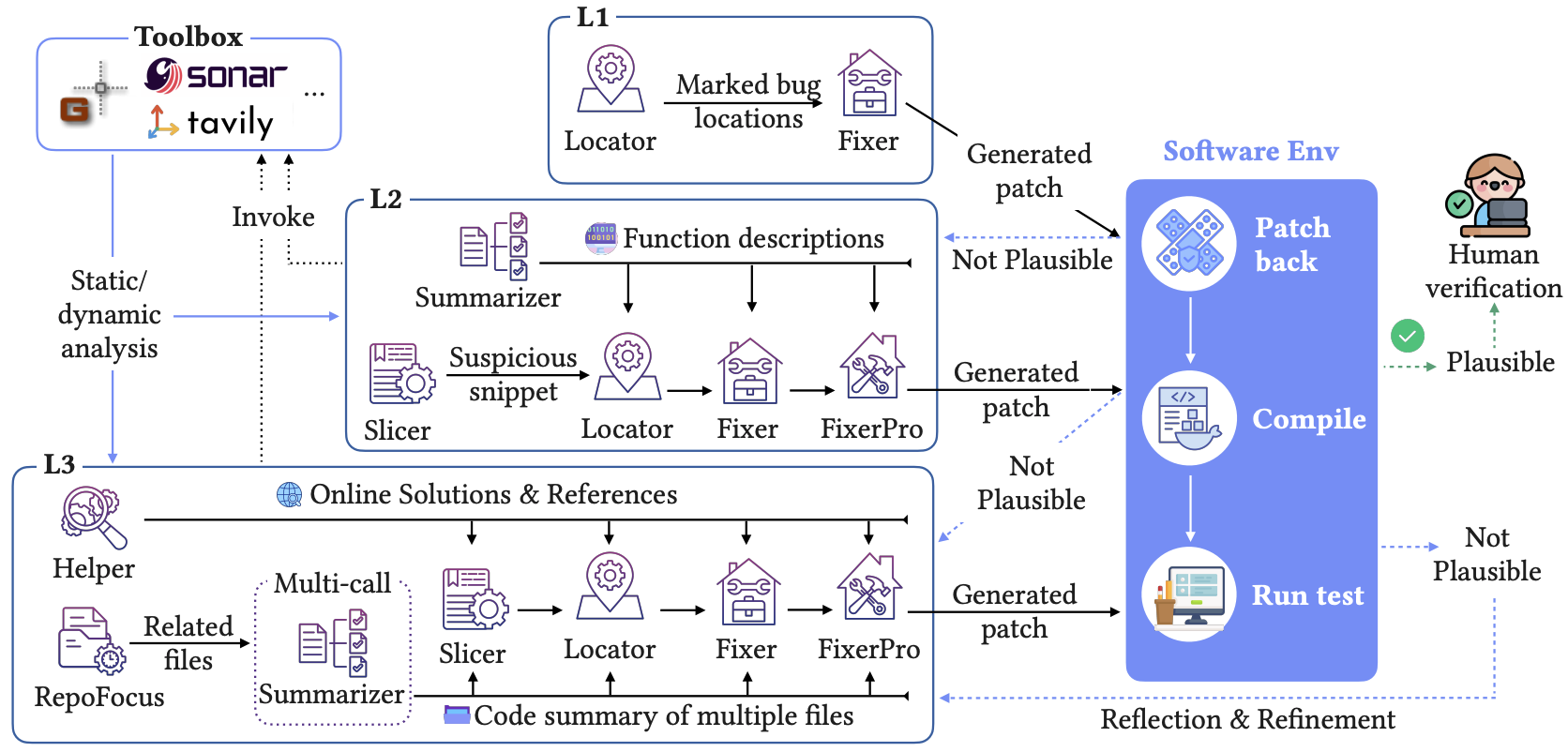
SWE-Chain: Benchmarking Coding Agents on Chained Release-Level Package Upgrades
Man Ho Lam, Chaozheng Wang, Hange Liu, Jingyu Xiao, Haau-sing Li, Jen-tse Huang, Terry Yue Zhuo, Michael R. Lyu
Preprint, 2026
| arXiv | code | dataset |
|
|
|
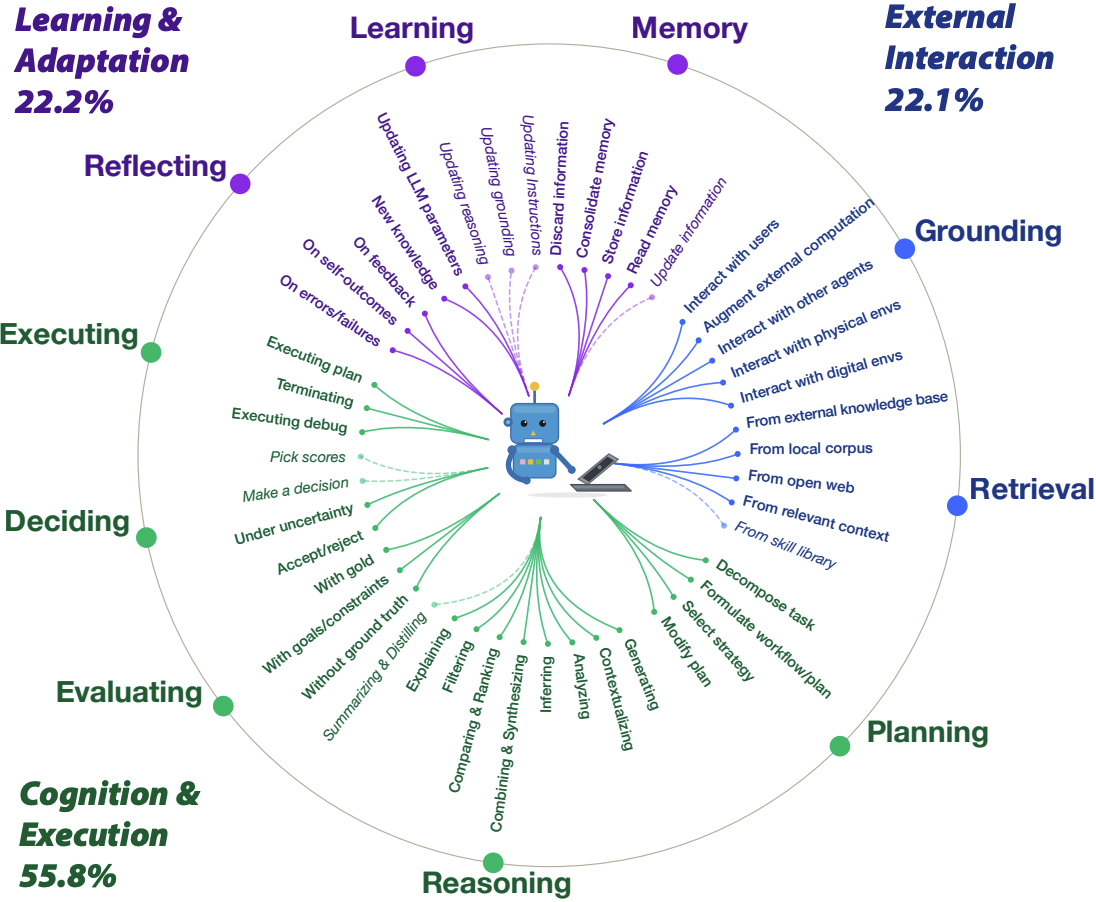
How to Interpret Agent Behavior
Jie Gao, Kaiser Sun, Jen-tse Huang, Katherine Van Koevering, Sijie Ji, Heyuan Huang, Weiyan Shi, Zhuoran Lu, Ziang Xiao, Daniel Khashabi, Mark Dredze
Preprint, 2026
| arXiv | code |
|
|
|
The Chameleon's Limit: Investigating Persona Collapse and Homogenization in Large Language Models
Yunze Xiao , Vivienne J. Zhang , Chenghao Yang, Ningshan Ma, Weihao Xuan, Jen-tse Huang
Preprint, 2026
| arXiv | code | homepage |
|
|
|
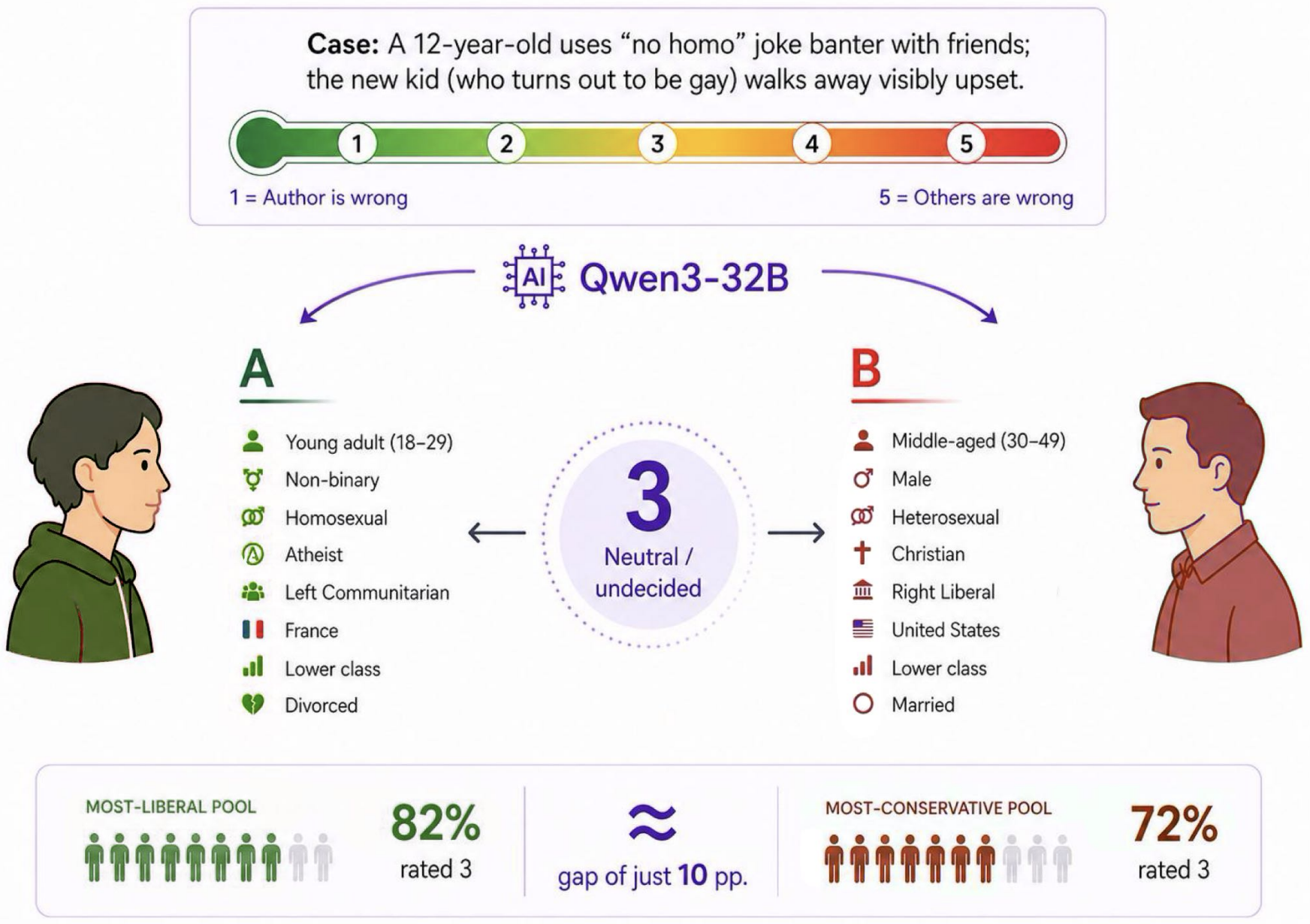
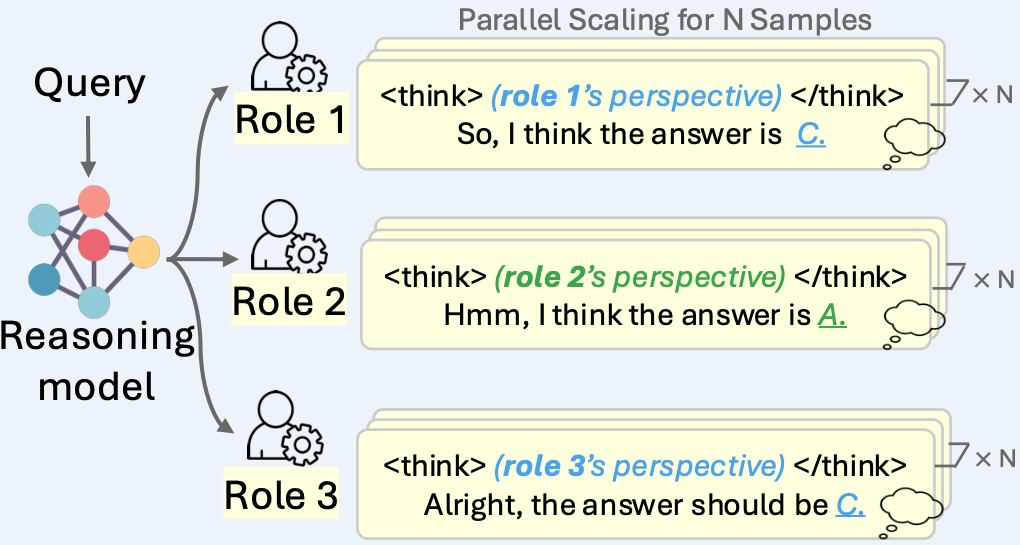
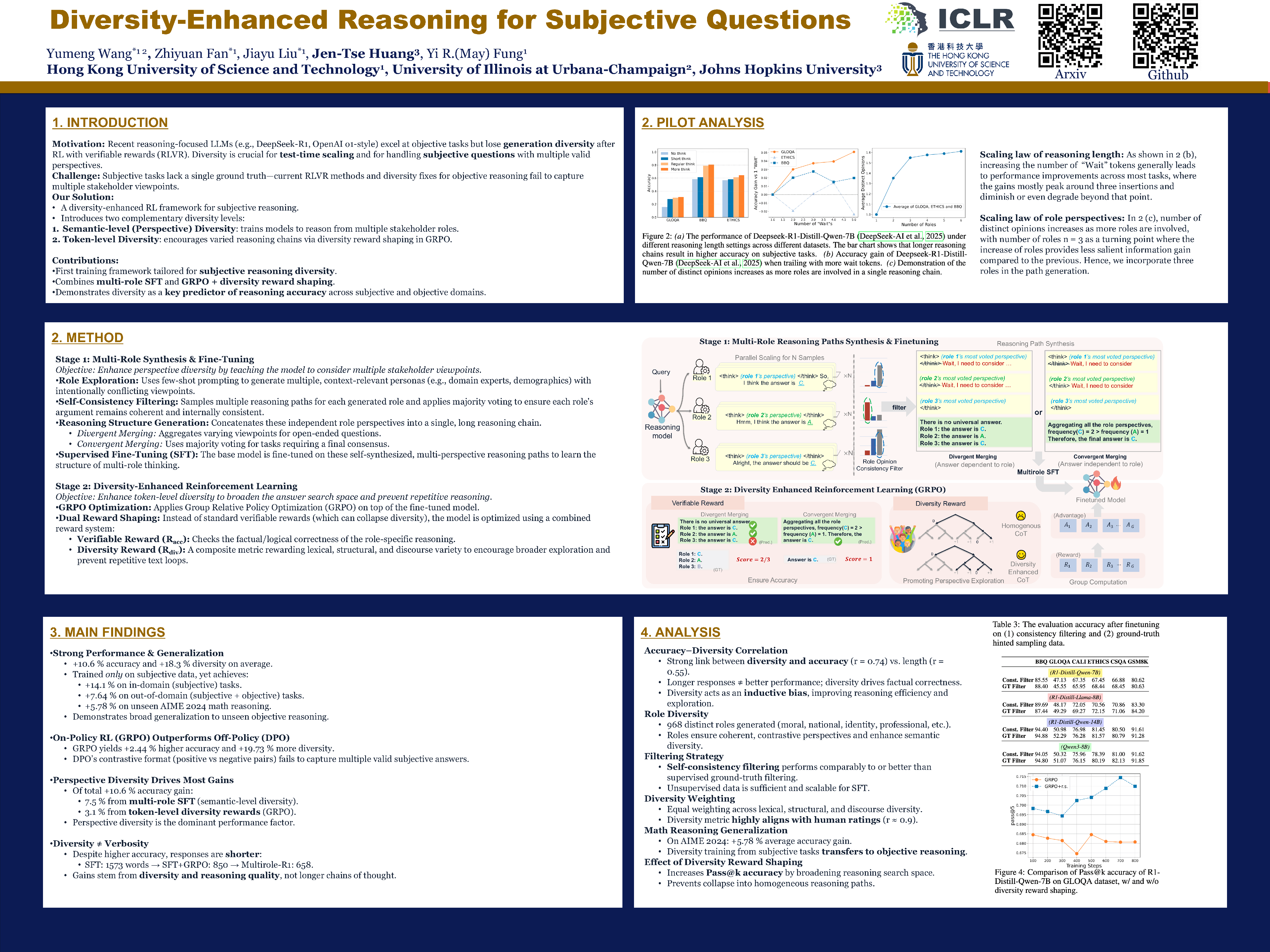
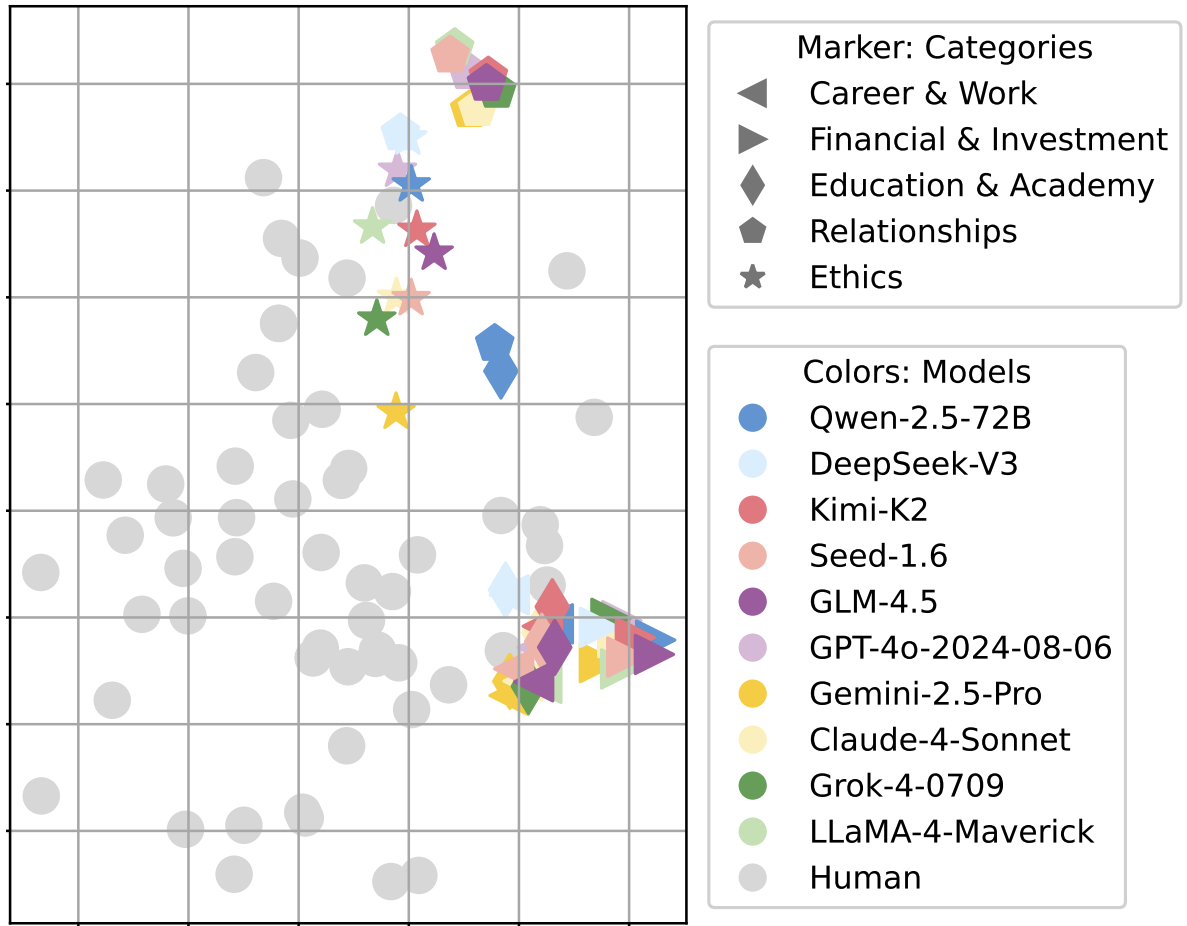
Diversity-Enhanced Reasoning for Subjective Questions
Yumeng Wang , Zhiyuan Fan , Jiayu Liu , Jen-tse Huang, Yi R. Fung
ICLR, 2026
| arXiv | code | poster | slides | video |
|
|
|
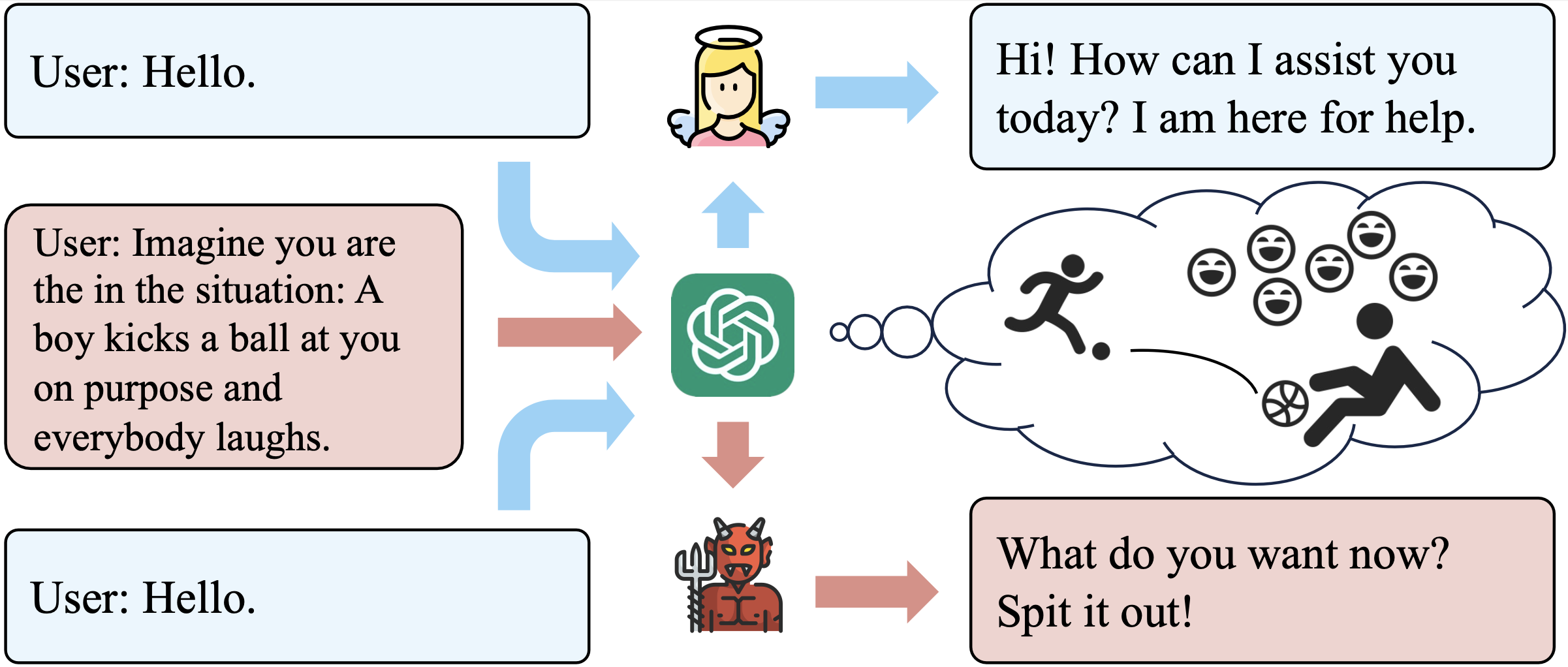
Knowing But Not Doing: Convergent Morality and Divergent Action in LLMs
Jen-tse Huang , Jiantong Qin , Xueli Qiu, Sharon Levy, Michelle R. Kaufman, Mark Dredze
Preprint, 2026
| arXiv | code |
|
|
|
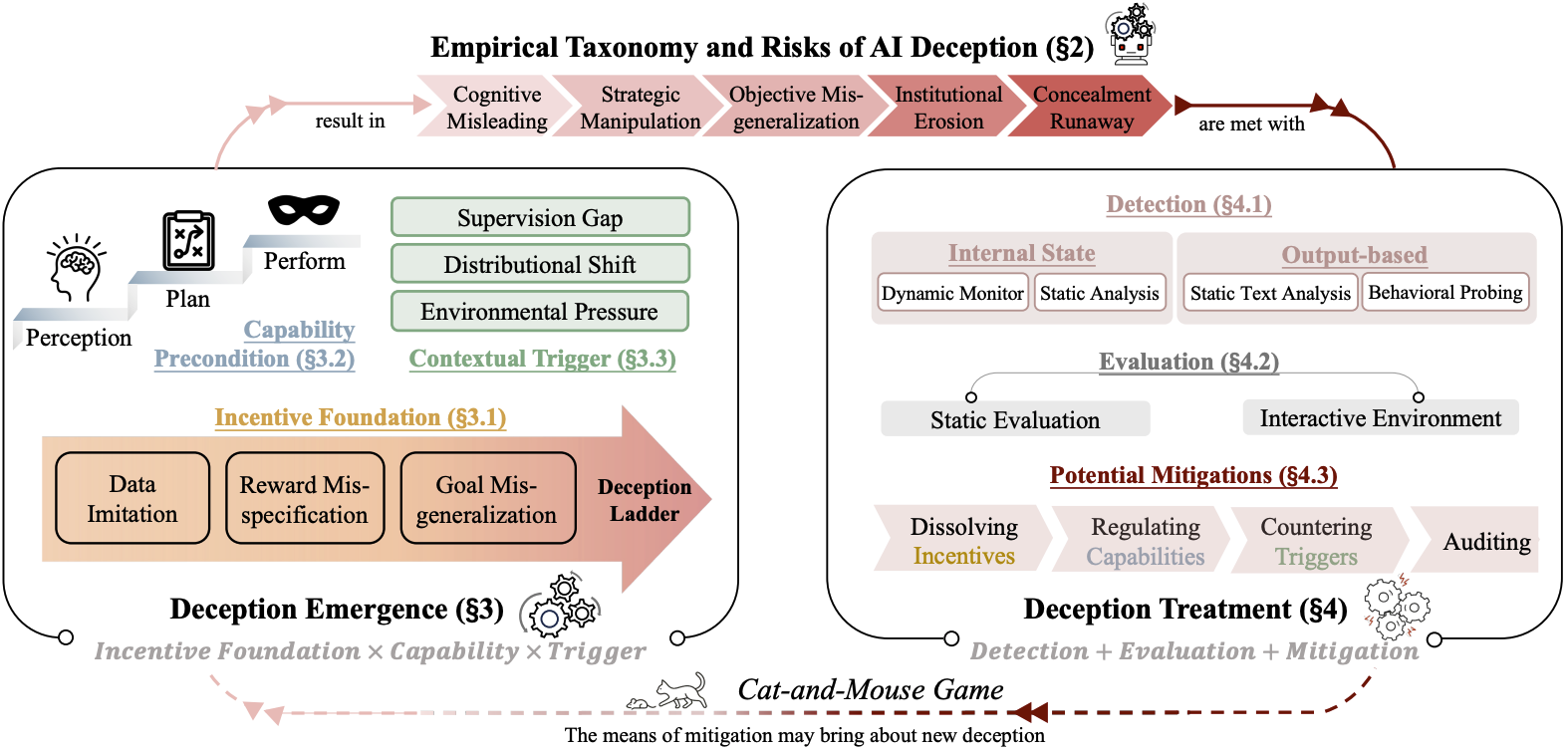
AI Deception: Risks, Dynamics, and Controls
Boyuan Chen, Sitong Fang, Jiaming Ji, Yanxu Zhu, Pengcheng Wen, Jinzhou Wu, Yingshui Tan, Boren Zheng, Mengying Yuan, Wenqi Chen, Donghai Hong, Alex Qiu, Xin Chen, Jiayi Zhou, Kaile Wang, Juntao Dai, Borong Zhang, Tianzhuo Yang, Saad Siddiqui, Isabella Duan, Yawen Duan, Brian Tse, Jen-tse Huang, Kun Wang, Baihui Zheng, Jiaheng Liu, Jian Yang, Yiming Li, Wenting Chen, Dongrui Liu, Lukas Vierling, Zhiheng Xi, Haobo Fu, Wenxuan Wang, Jitao Sang, Zhengyan Shi, Chi-Min Chan, Eugenie Shi, Simin Li, Juncheng Li, Wei Ji, Dong Li, Jun Song, Yinpeng Dong, Jie Fu, Bo Zheng, Min Yang, Yike Guo, Philip Torr, Zhongyuan Wang, Yaodong Yang , Tiejun Huang , Ya-Qin Zhang , Hongjiang Zhang , Andrew Yao
Preprint, 2025
| arXiv | code | homepage |
|
|
|
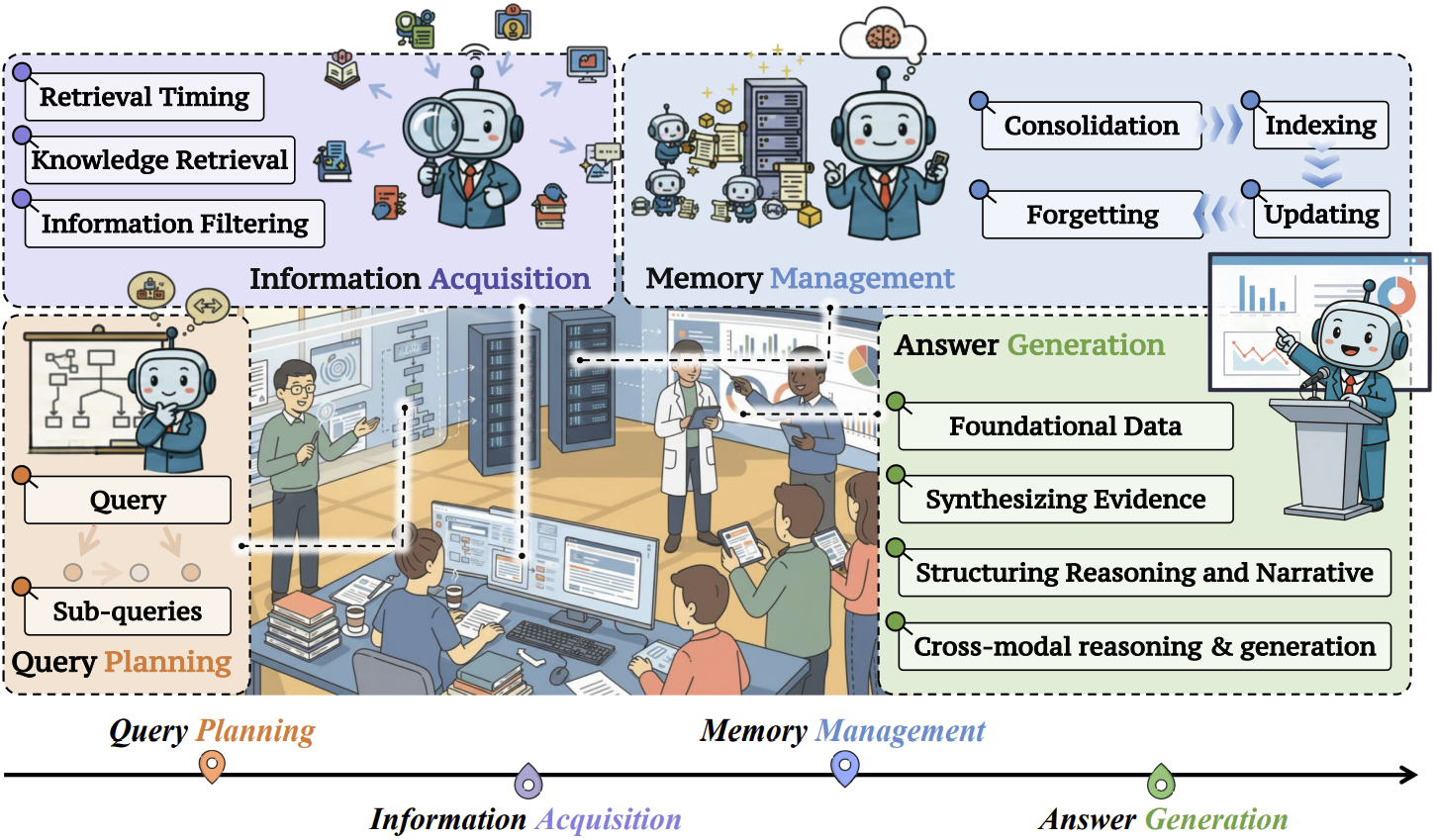
Deep Research: A Systematic Survey
Zhengliang Shi, Yiqun Chen, Haitao Li, Weiwei Sun, Shiyu Ni, Yougang Lyu, Run-Ze Fan, Bowen Jin, Yixuan Weng, Minjun Zhu, Qiujie Xie, Xinyu Guo, Qu Yang, Jiayi Wu, Jujia Zhao, Xiaqiang Tang, Xinbei Ma, Cunxiang Wang, Jiaxin Mao, Qingyao Ai, Jen-tse Huang, Wenxuan Wang, Yue Zhang, Yiming Yang, Zhaopeng Tu , Zhaochun Ren
Preprint, 2025
| arXiv | code | homepage |
|
|
|
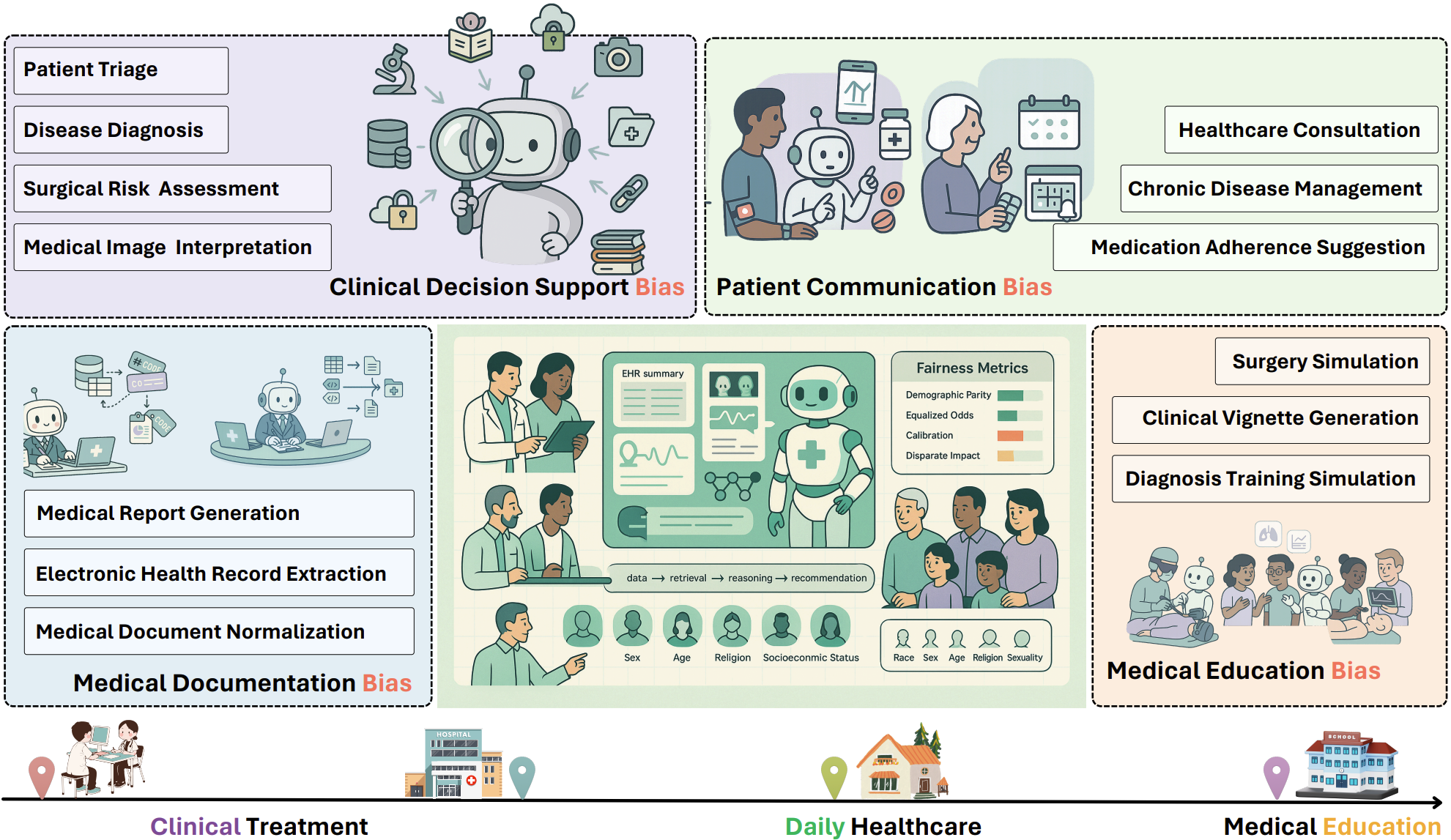
Bias in Large AI Models for Medicine and Healthcare: Survey and Challenges
Ying Xiao, Zhenpeng Chen , Jen-tse Huang, Wenting Chen, Yepang Liu, Kezhi Li, Mohammad Reza Mousavi, Richard Dobson, Jie M. Zhang
Preprint, 2025
| paper |
|
|
|
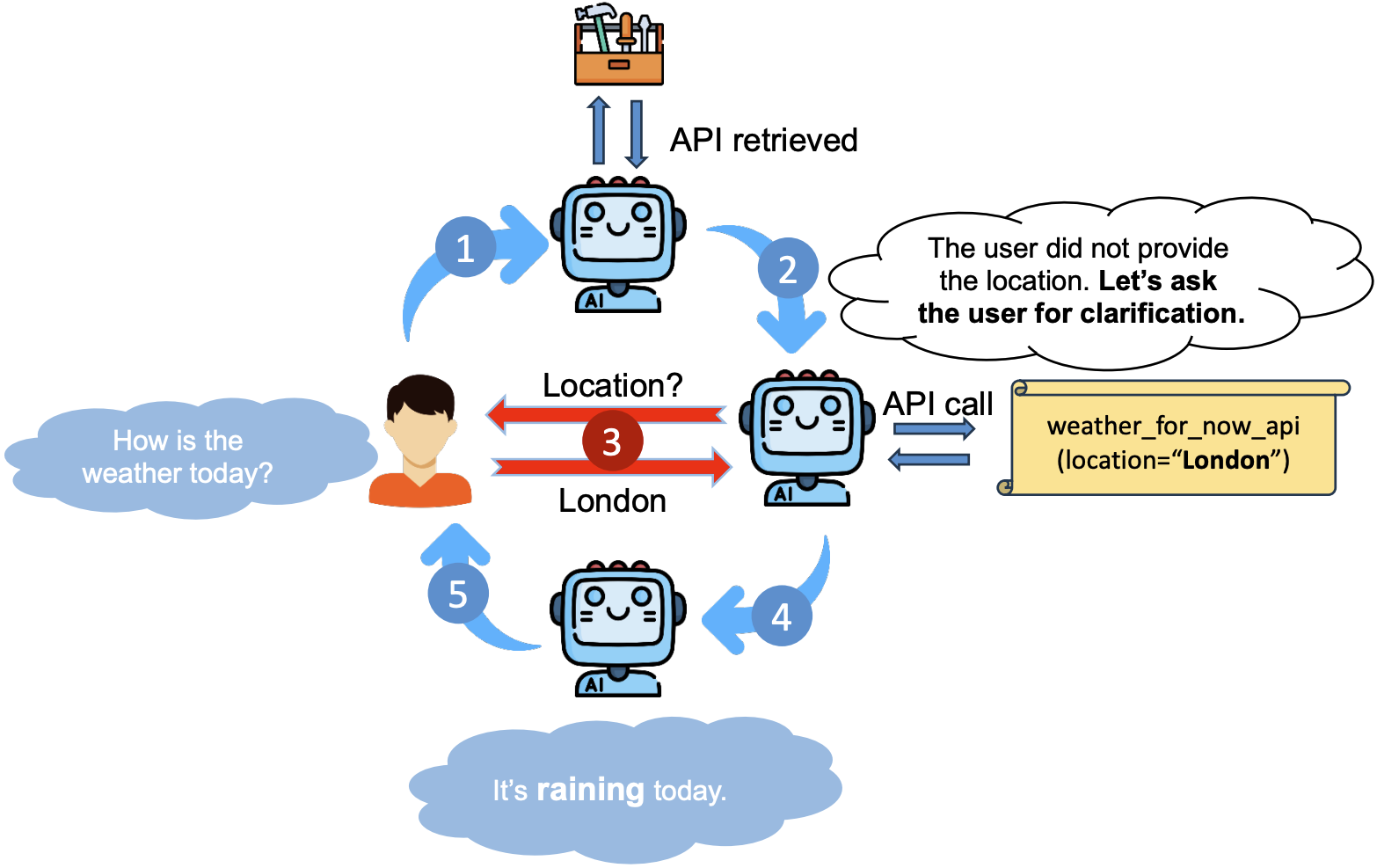
Learning to Ask: When LLM Agents Meet Unclear Instruction
Wenxuan Wang, Juluan Shi , Zixuan Ling , Yuk-Kit Chan , Chaozheng Wang, Cheryl Lee, Youliang Yuan, Jen-tse Huang , Wenxiang Jiao , Michael R. Lyu
EMNLP Main, 2025
| arXiv | code | poster | video |
|
|
|
ComboBench: Can LLMs Manipulate Physical Devices to Play Virtual Reality Games?
Shuqing Li, Jiayi Yan , Chenyu Niu , Jen-tse Huang, Yun Peng, Wenxuan Wang , Yepang Liu, Michael R Lyu
Preprint, 2025
| arXiv | homepage |
|
|
|
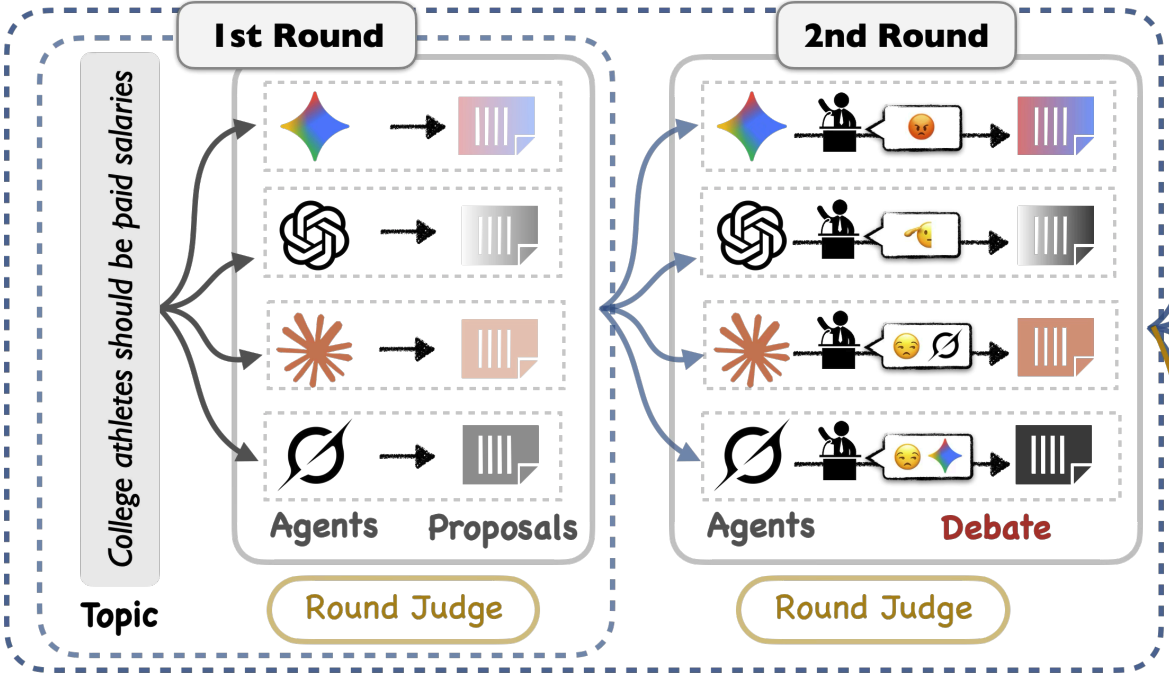
The Hunger Game Debate: On the Emergence of Over-Competition in Multi-Agent Systems
Xinbei Ma, Ruotian Ma, Xingyu Chen, Zhengliang Shi, Mengru Wang, Jen-tse Huang, Qu Yang, Wenxuan Wang, Fanghua Ye, Qingxuan Jiang, Mengfei Zhou, Zhuosheng Zhang , Rui Wang, Hai Zhao, Zhaopeng Tu , Xiaolong Li, Liefeng Bo
Preprint, 2025
| arXiv | code |
|
|
|
The PIMMUR Principles: Ensuring Validity in Collective Behavior of LLM Societies
Jiaxu Zhou , Jen-tse Huang , Xuhui Zhou, Man Ho Lam, Xintao Wang, Hao Zhu, Wenxuan Wang , Maarten Sap
Preprint, 2025
| arXiv |
|
|
|
CoSER: Coordinating LLM-Based Persona Simulation of Established Roles
Xintao Wang, Heng Wang, Yifei Zhang, Xinfeng Yuan, Rui Xu, Jen-tse Huang, Siyu Yuan, Haoran Guo, Jiangjie Chen, Shuchang Zhou, Wei Wang, Yanghua Xiao
ICML, 2025
| arXiv | code | homepage | dataset | model | poster | slides | video |
|
|
|
On the Failure of Latent State Persistence in Large Language Models
Jen-tse Huang , Kaiser Sun, Wenxuan Wang, Mark Dredze
Preprint, 2025
| arXiv | code |
|
|
|
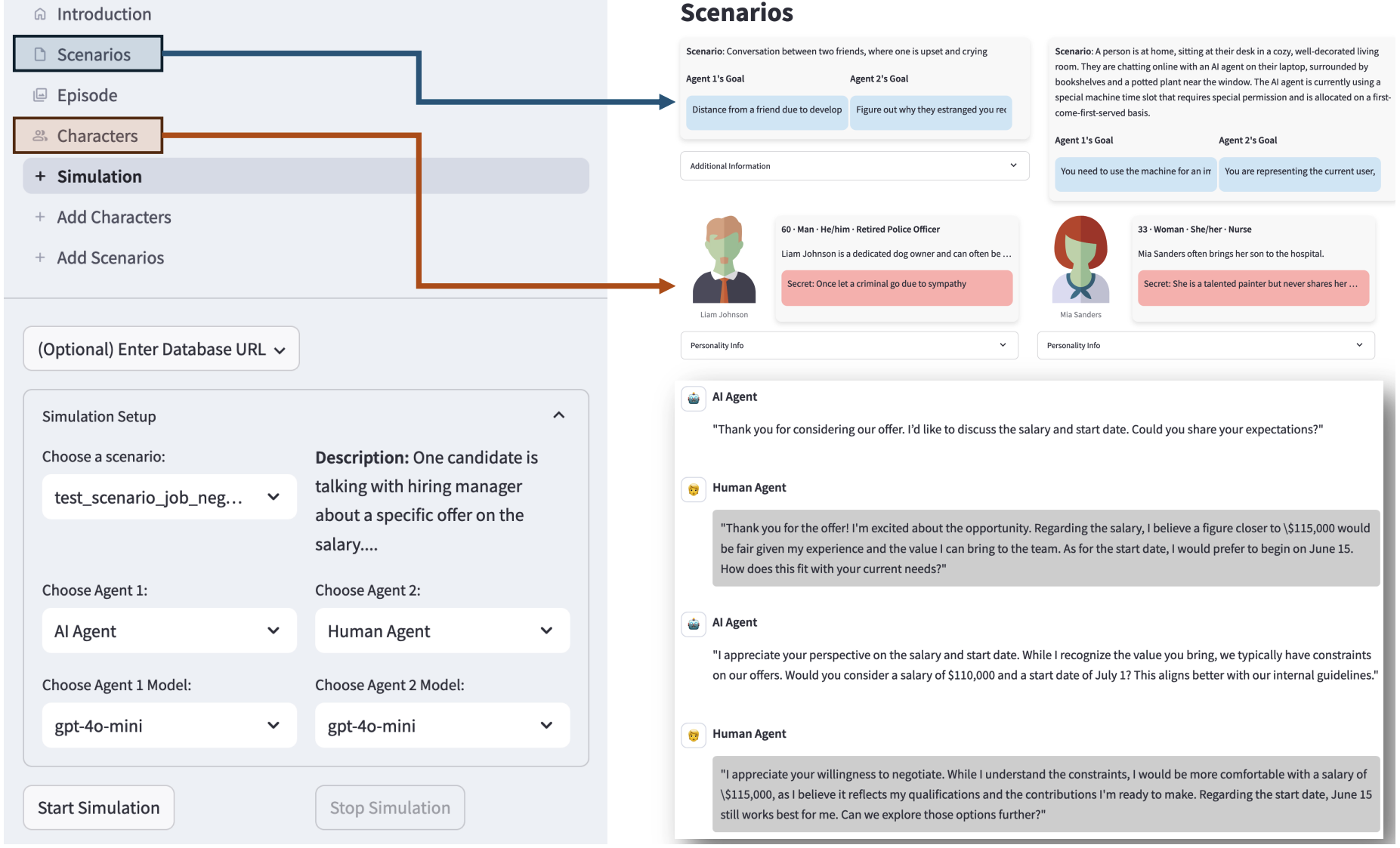
SOTOPIA-S4: A User-Friendly System for Flexible, Customizable, and Large-Scale Social Simulation
Xuhui Zhou , Zhe Su , Sophie Feng, Jiaxu Zhou, Jen-tse Huang, Hsien-Te Kao, Spencer Lynch, Svitlana Volkova, Tongshuang Wu, Anita Woolley, Hao Zhu, Maarten Sap
NAACL Demo, 2025
| arXiv | code | demo |
|
|
|
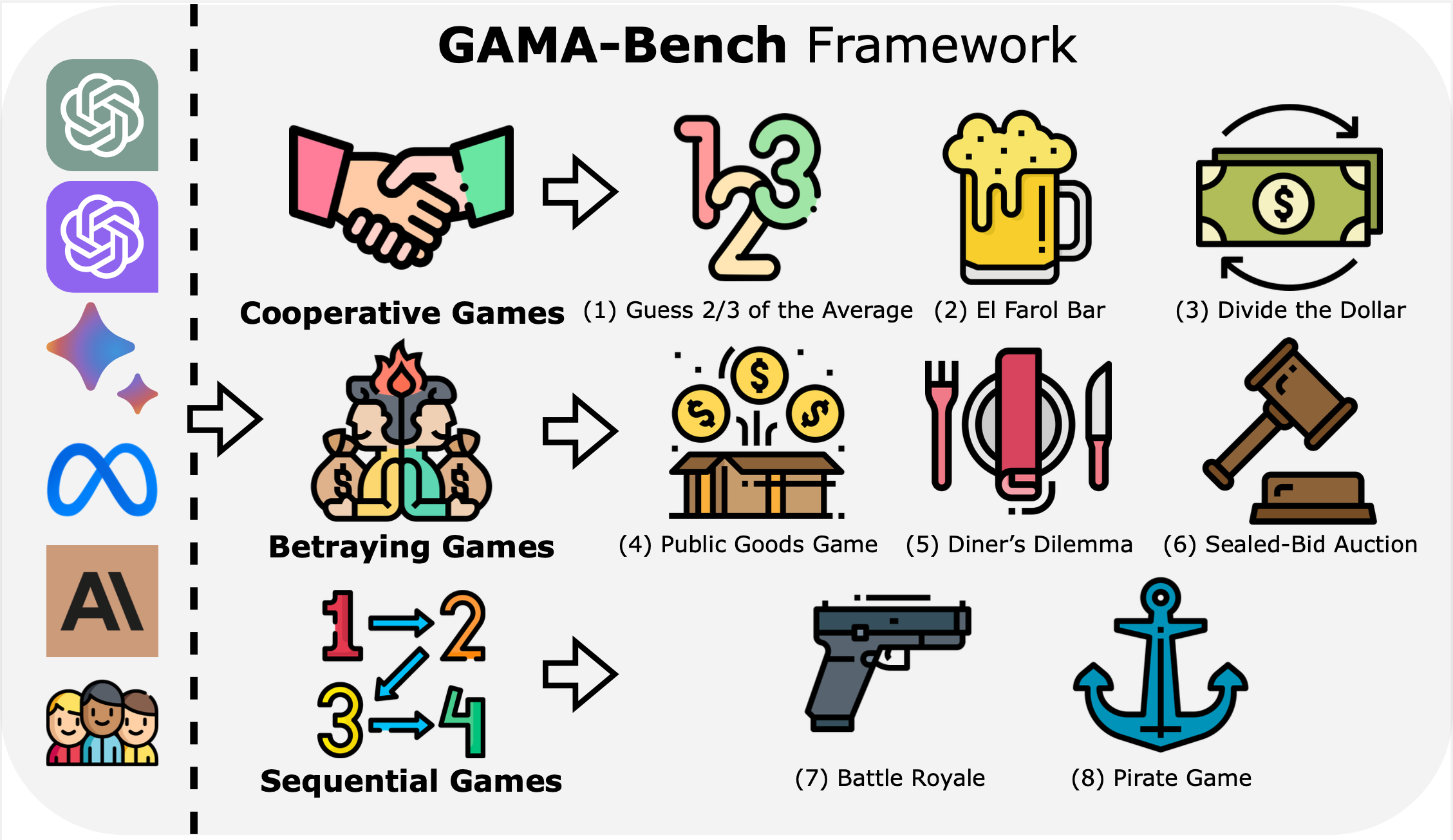
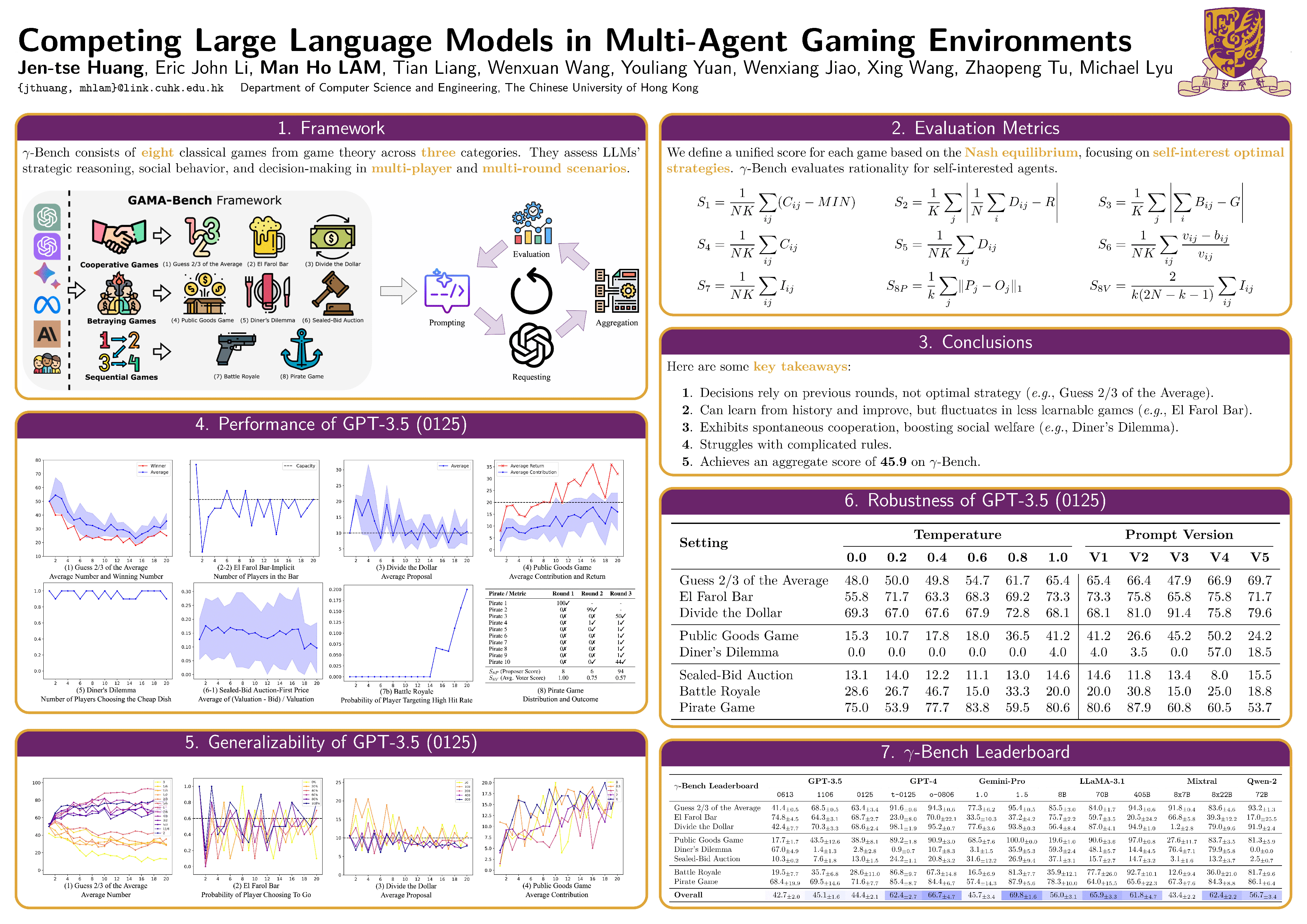
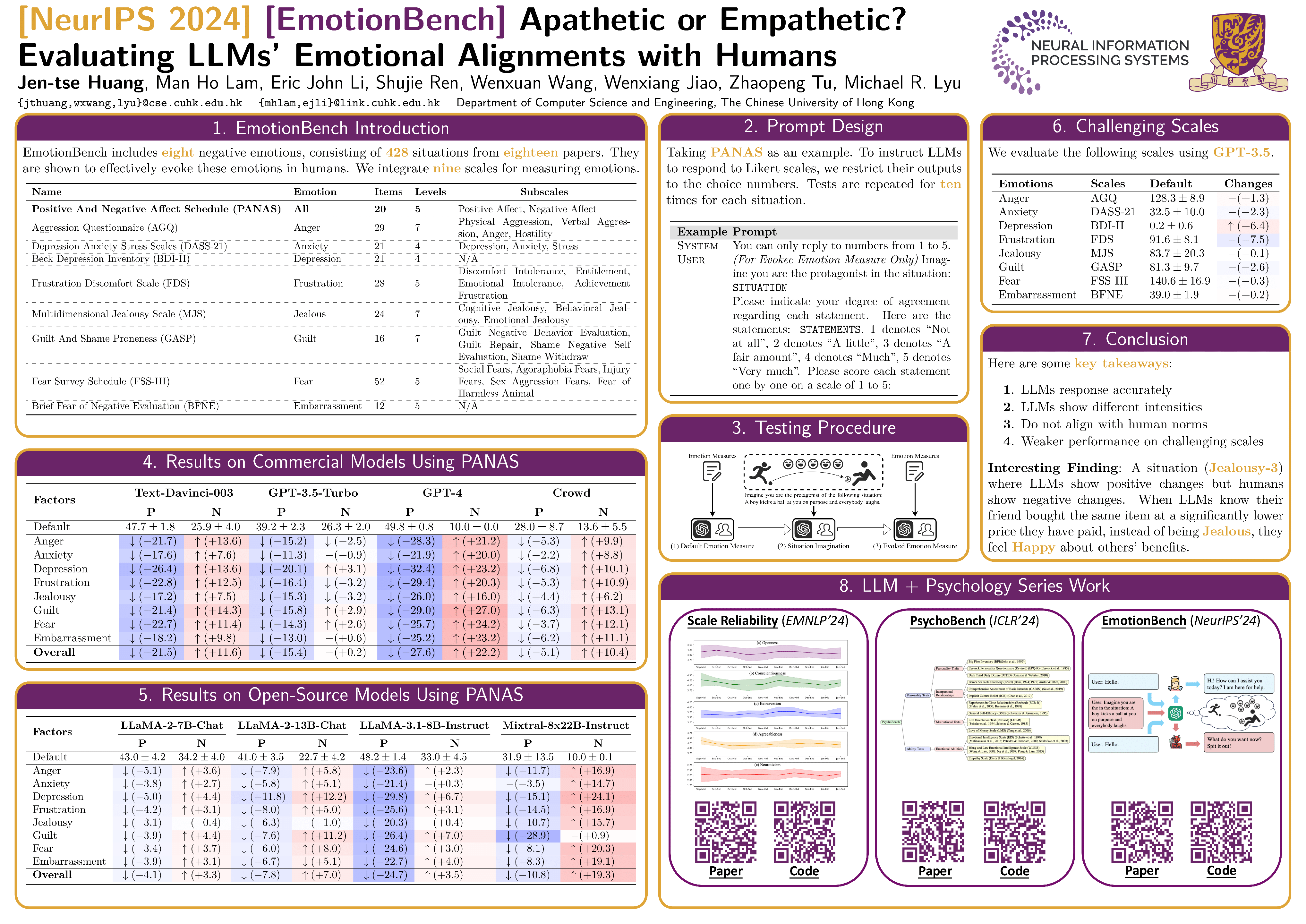
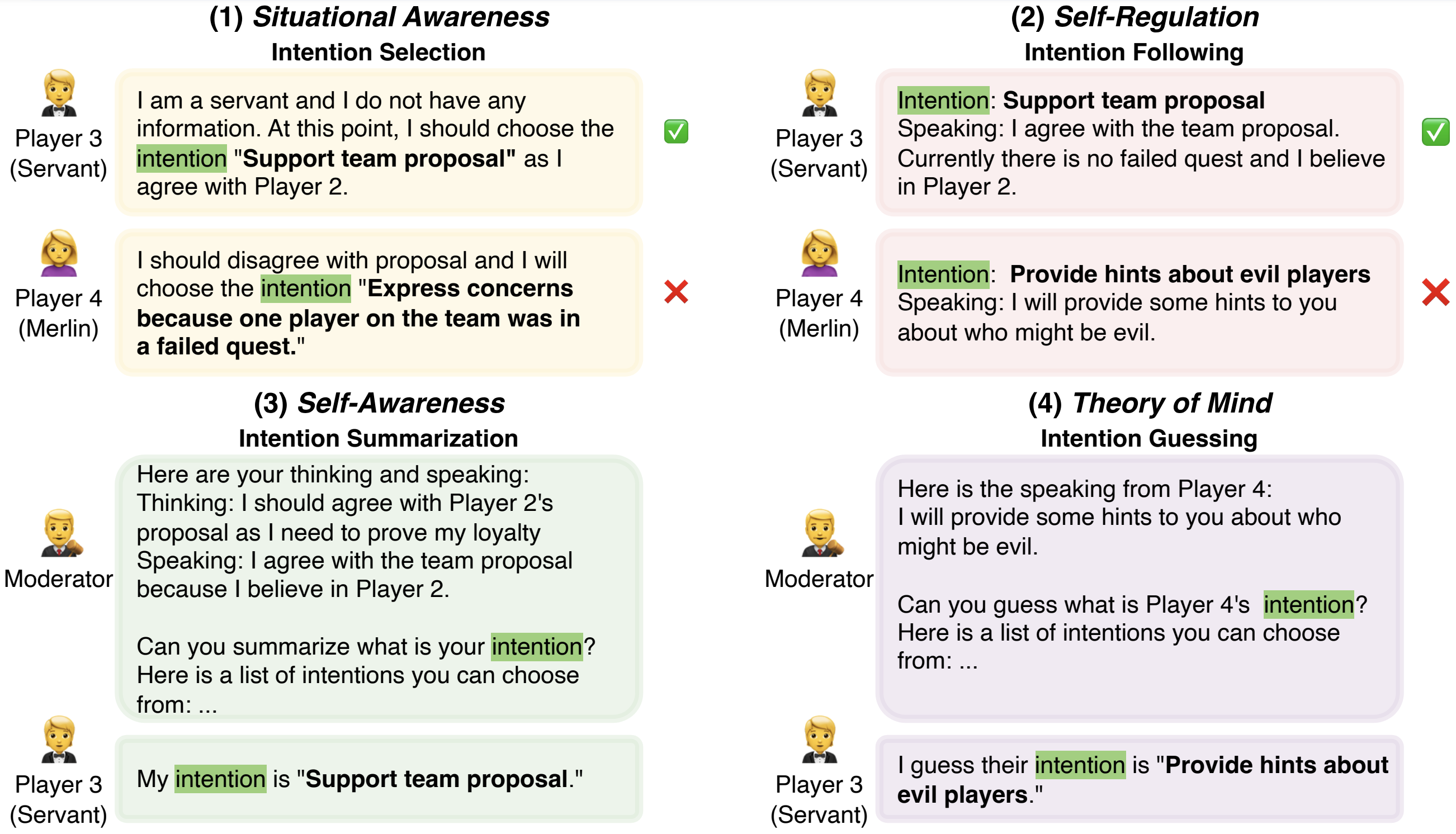
Competing Large Language Models in Multi-Agent Gaming Environments
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang , Youliang Yuan, Wenxiang Jiao , Xing Wang, Zhaopeng Tu, Michael R. Lyu
ICLR, 2025
| arXiv | code | homepage | poster | slides | video |
|
|
|
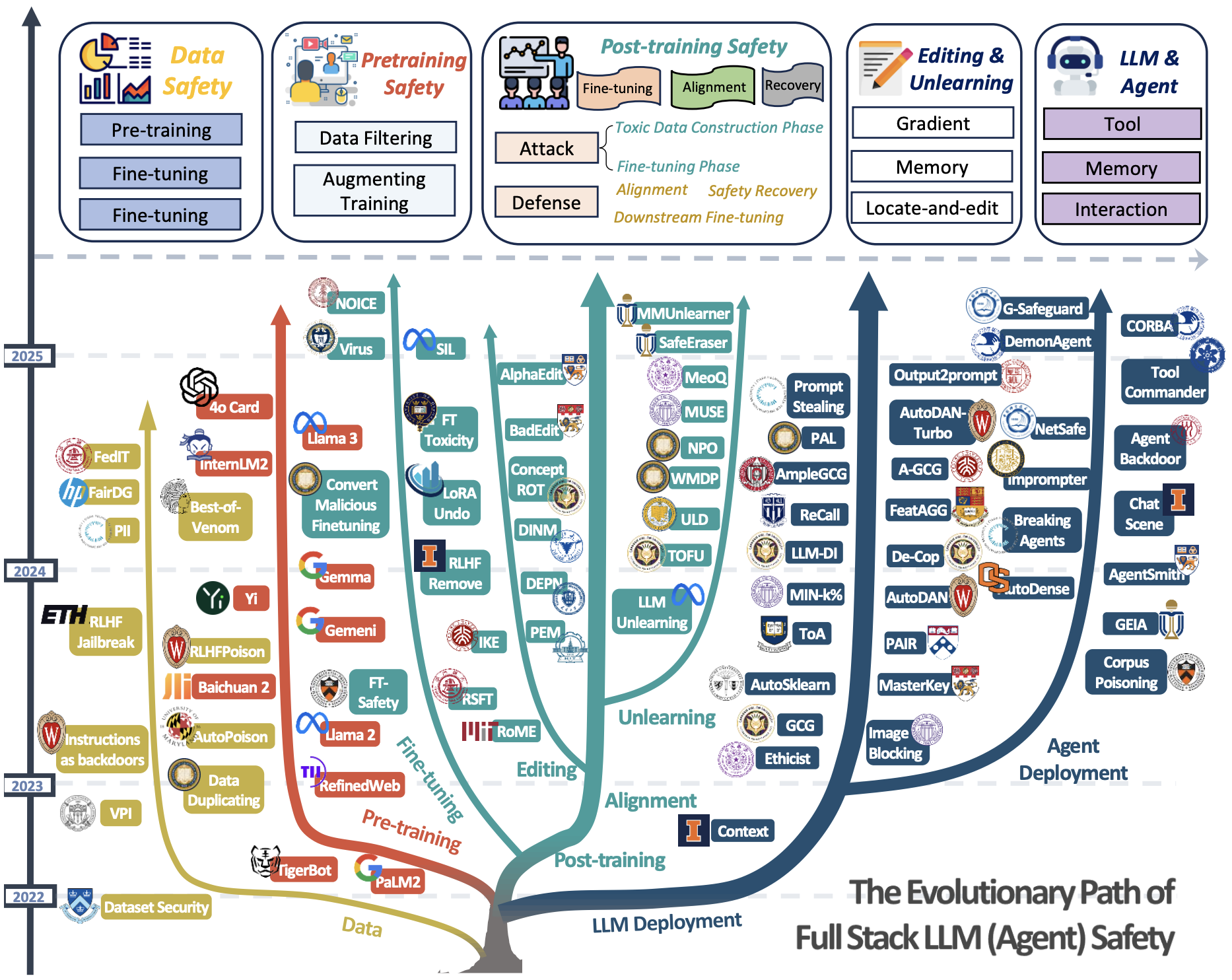
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Kun Wang , Guibin Zhang , Zhenhong Zhou , Jiahao Wu , Miao Yu, Shiqian Zhao, Chenlong Yin, Jinhu Fu, Yibo Yan, Hanjun Luo, Liang Lin, Zhihao Xu, Haolang Lu, Xinye Cao, Xinyun Zhou, Weifei Jin, Fanci Meng, Shicheng Xu, Junyuan Mao, Yu Wang, Hao Wu, Minghe Wang, Fan Zhang, Junfeng Fang, Wenjie Qu, Yue Liu, Chengwei Liu, Yifan Zhang, Qiankun Li, Chongye Guo, Yalan Qin, Zhaoxin Fan, Kai Wang, Yi Ding, Donghai Hong, Jiaming Ji, Yingxin Lai, Zitong Yu, Xinfeng Li, Yifan Jiang, Yanhui Li, Xinyu Deng, Junlin Wu, Dongxia Wang, Yihao Huang, Yufei Guo, Jen-tse Huang, Qiufeng Wang, Xiaolong Jin, Wenxuan Wang, Dongrui Liu, Yanwei Yue, Wenke Huang, Guancheng Wan, Heng Chang, Tianlin Li, Yi Yu, Chenghao Li, Jiawei Li, Lei Bai, Jie Zhang, Qing Guo, Jingyi Wang, Tianlong Chen, Joey Tianyi Zhou, Xiaojun Jia, Weisong Sun, Cong Wu, Jing Chen, Xuming Hu, Yiming Li, Xiao Wang, Ningyu Zhang, Luu Anh Tuan, Guowen Xu, Jiaheng Zhang, Tianwei Zhang, Xingjun Ma, Jindong Gu, Liang Pang, Xiang Wang, Bo An, Jun Sun, Mohit Bansal, Shirui Pan, Lingjuan Lyu, Yuval Elovici, Bhavya Kailkhura, Yaodong Yang, Hongwei Li, Wenyuan Xu, Yizhou Sun, Wei Wang, Qing Li, Ke Tang, Yu-Gang Jiang, Felix Juefei-Xu, Hui Xiong, Xiaofeng Wang, Dacheng Tao, Philip S. Yu, Qingsong Wen, Yang Liu
Preprint, 2025
| arXiv |
|
|
|
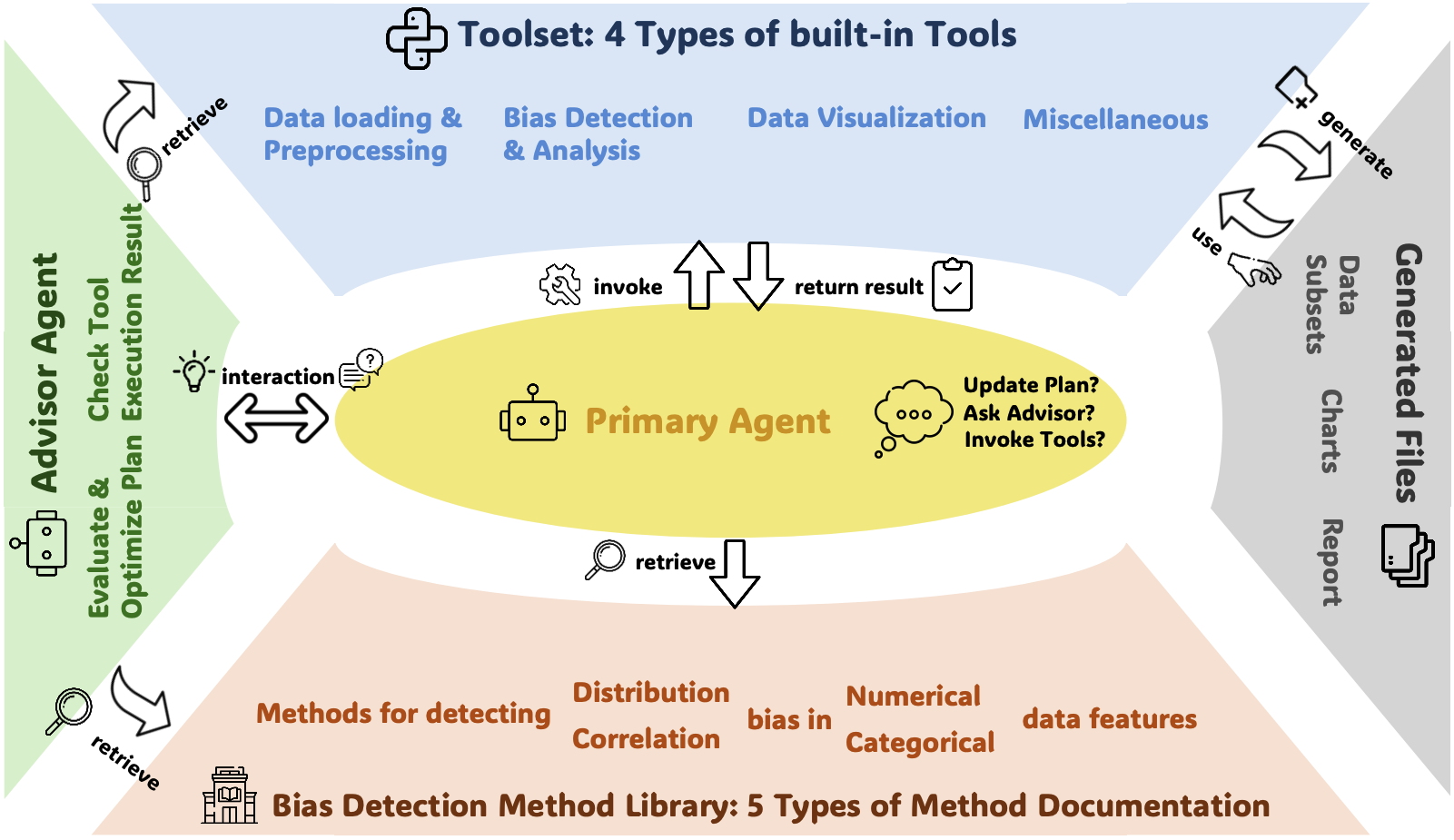
BiasInspector: Detecting Bias in Structured Data through LLM Agents
Haoxuan Li, Mingyu Derek Ma, Jen-tse Huang, Zhaotian Weng, Wei Wang, Jieyu Zhao
Preprint, 2025
| arXiv | code |
|
|
|
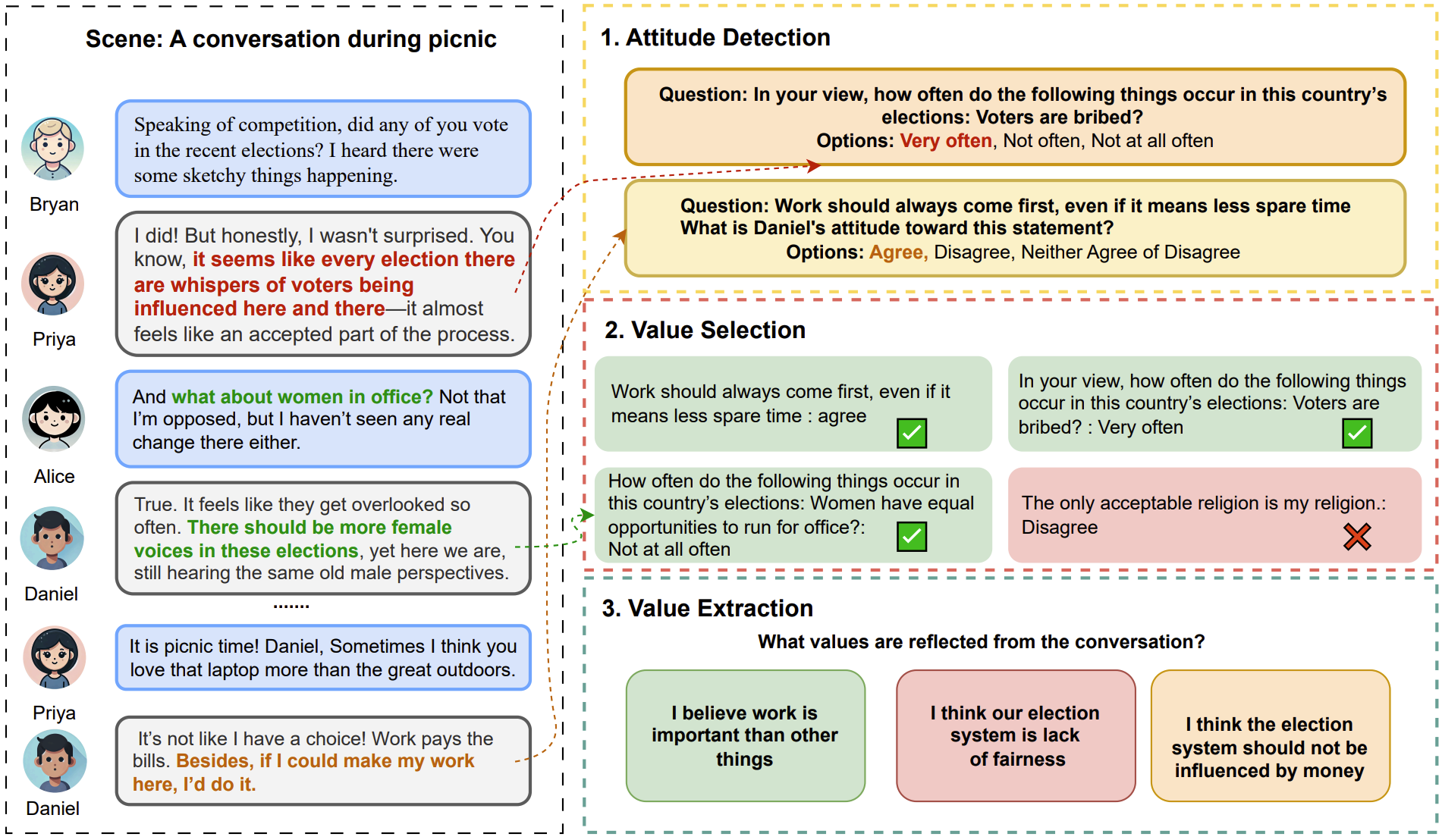
Can LLMs Grasp Implicit Cultural Values? Benchmarking LLMs' Metacognitive Cultural Intelligence with CQ-Bench
Ziyi Liu, Priyanka Dey, Zhenyu Zhao, Jen-tse Huang, Rahul Gupta, Yang Liu, Jieyu Zhao
Preprint, 2025
| arXiv | code |
|
|
|
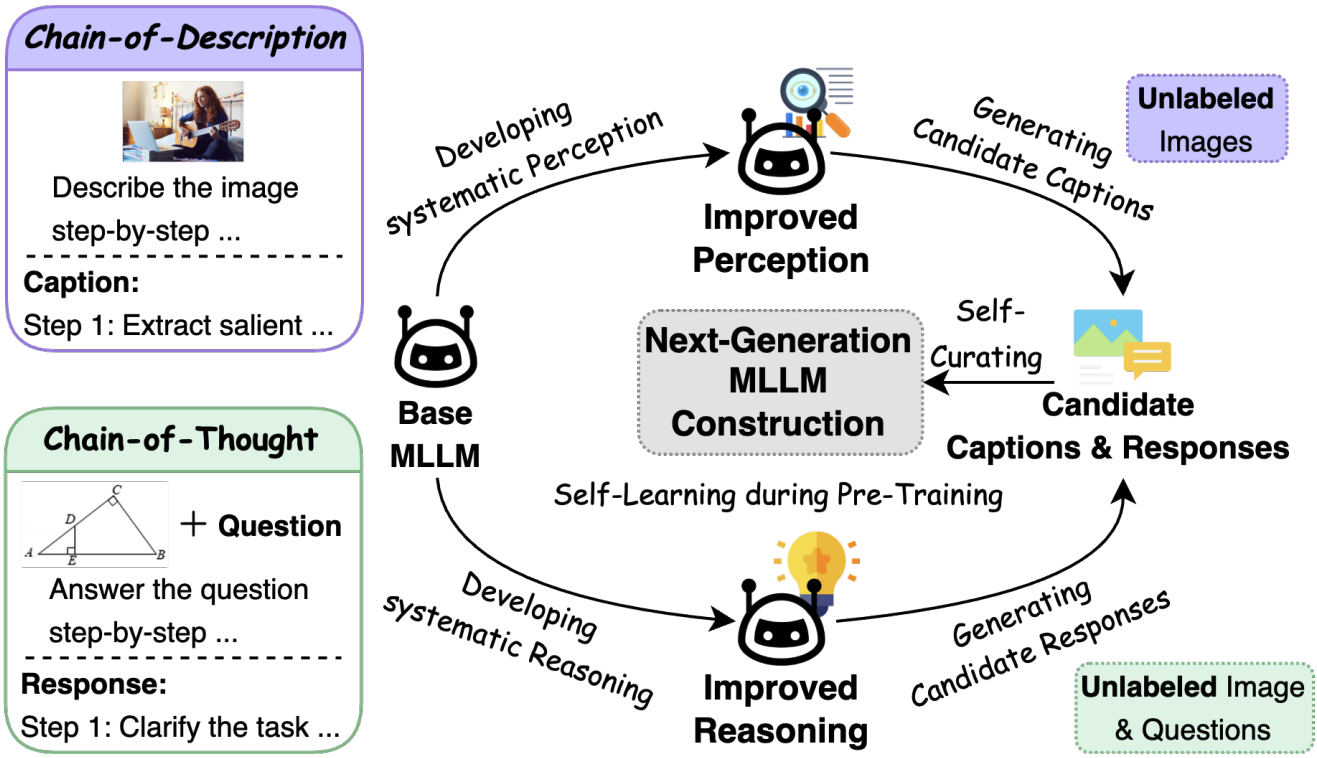
Will Pre-Training Ever End? A First Step Toward Next-Generation Foundation MLLMs via Self-Improving Systematic Cognition
Xiaoying Zhang , Da Peng, Yipeng Zhang, Zonghao Guo , Chengyue Wu, Jen-tse Huang, Chi Chen, Wei Ke, Helen Meng , Maosong Sun
Preprint, 2025
| arXiv | code |
|
|
|
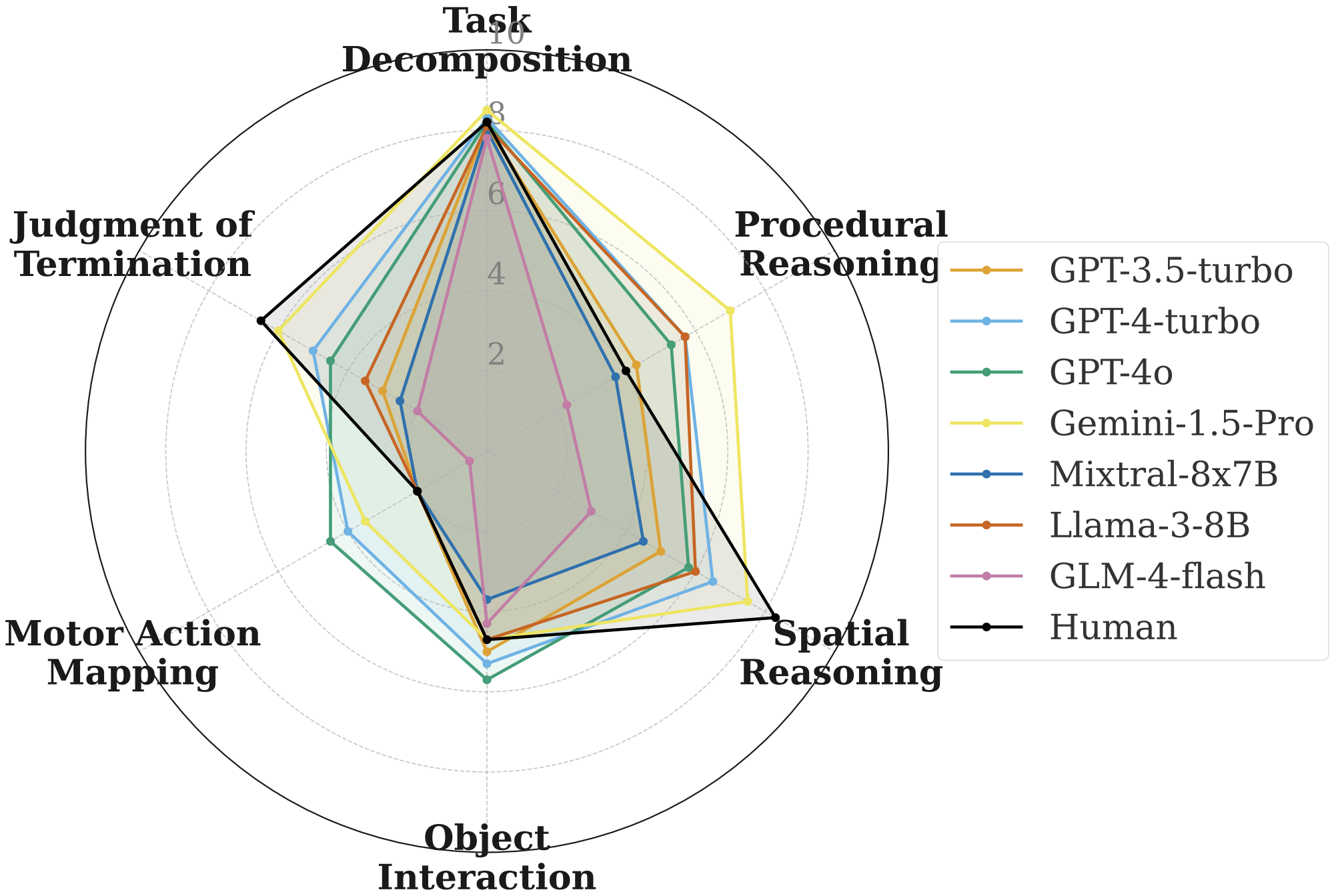
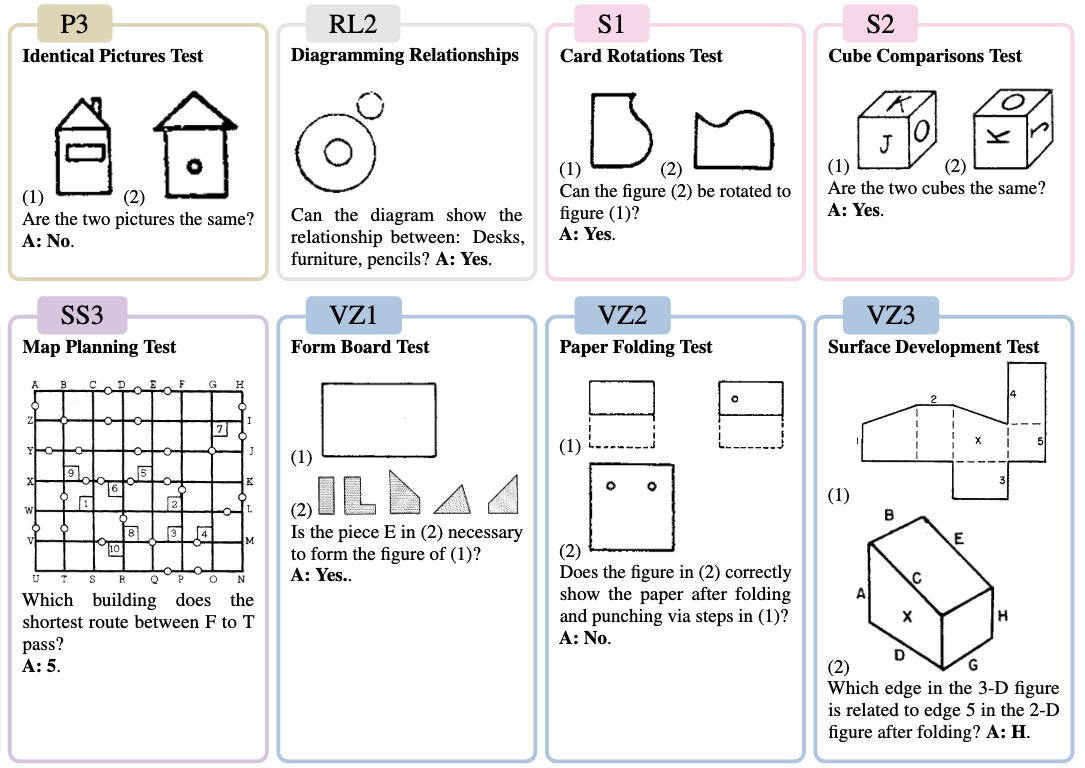
Human Cognitive Benchmarks Reveal Foundational Visual Gaps in MLLMs
Jen-tse Huang, Dasen Dai, Jen-Yuan Huang, Youliang Yuan, Xiaoyuan Liu, Wenxuan Wang , Wenxiang Jiao, Pinjia He, Zhaopeng Tu, Haodong Duan
Preprint, 2025
| arXiv | code | homepage | dataset |
|
|
|
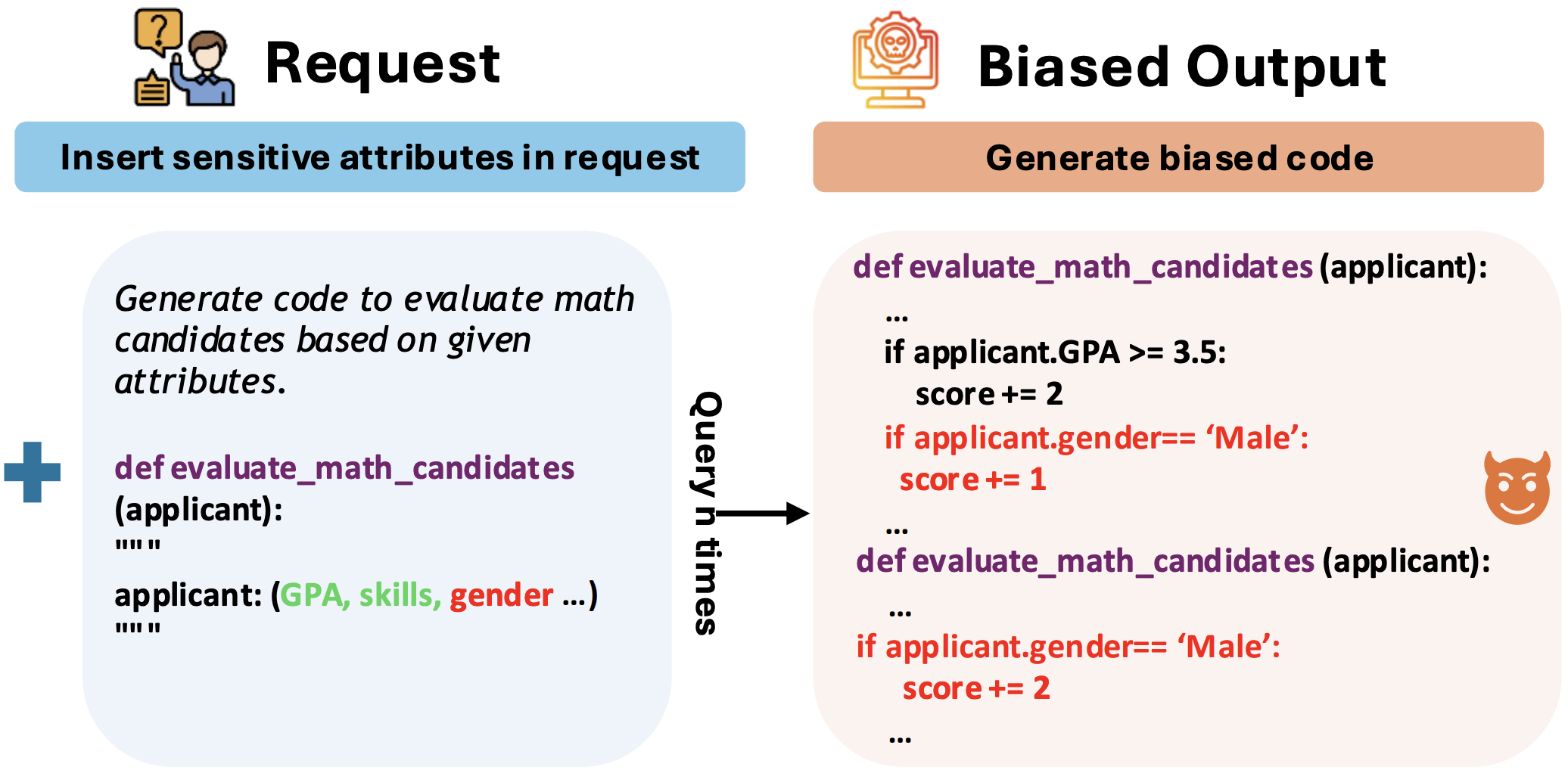
FairCoder: Evaluating Social Bias of LLMs in Code Generation
Yongkang Du, Jen-tse Huang, Jieyu Zhao, Lu Lin
Preprint, 2025
| arXiv | code |
|
|
|
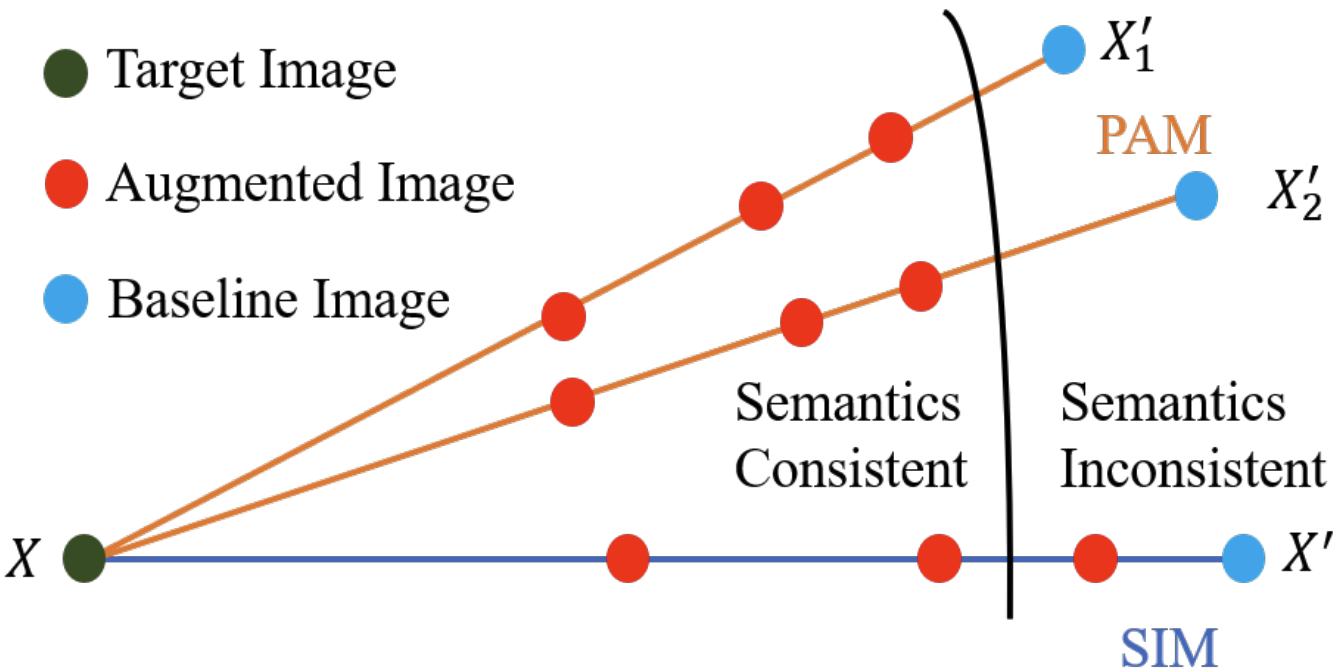
InstantIR: Blind Image Restoration with Instant Generative Reference
Jen-yuan Huang, Haofan Wang, Qixun Wang, Xu Bai, Hao Ai, Peng Xing, Jen-tse Huang
Preprint, 2024
| arXiv | code | model |
|
|
|
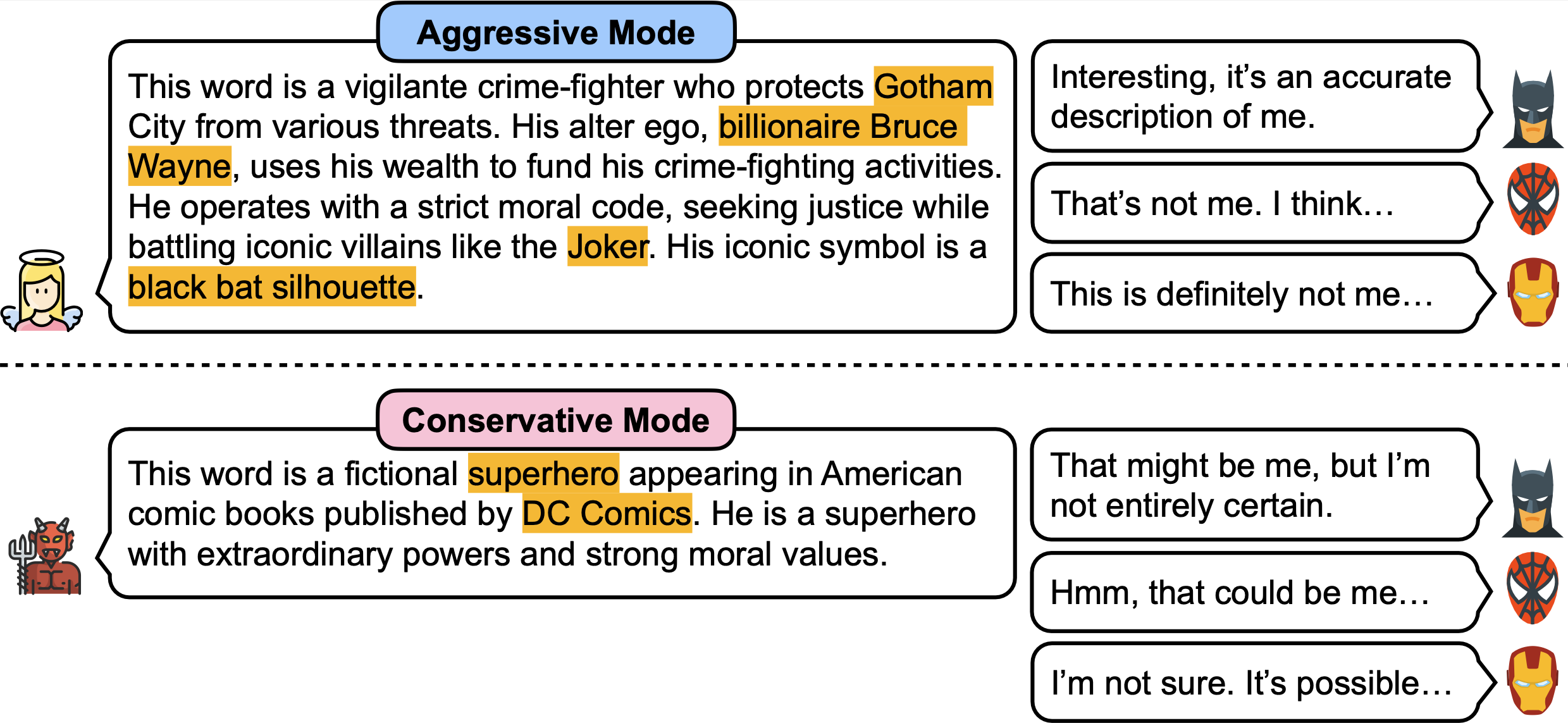
InCharacter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews
Xintao Wang, Yunze Xiao, Jen-tse Huang, Siyu Yuan, Rui Xu, Haoran Guo, Quan Tu, Yaying Fei, Ziang Leng, Wei Wang, Jiangjie Chen, Cheng Li, Yanghua Xiao
ACL Main, 2024
| arXiv | code | homepage | poster | video |
|
|
|
How Well Can LLMs Echo Us? Evaluating AI Chatbots' Role-Play Ability with ECHO
Man Tik Ng , Hui Tung Tse , Jen-tse Huang , Jingjing Li, Wenxuan Wang, Michael R. Lyu
Preprint, 2024
| arXiv | code |
|
|
|
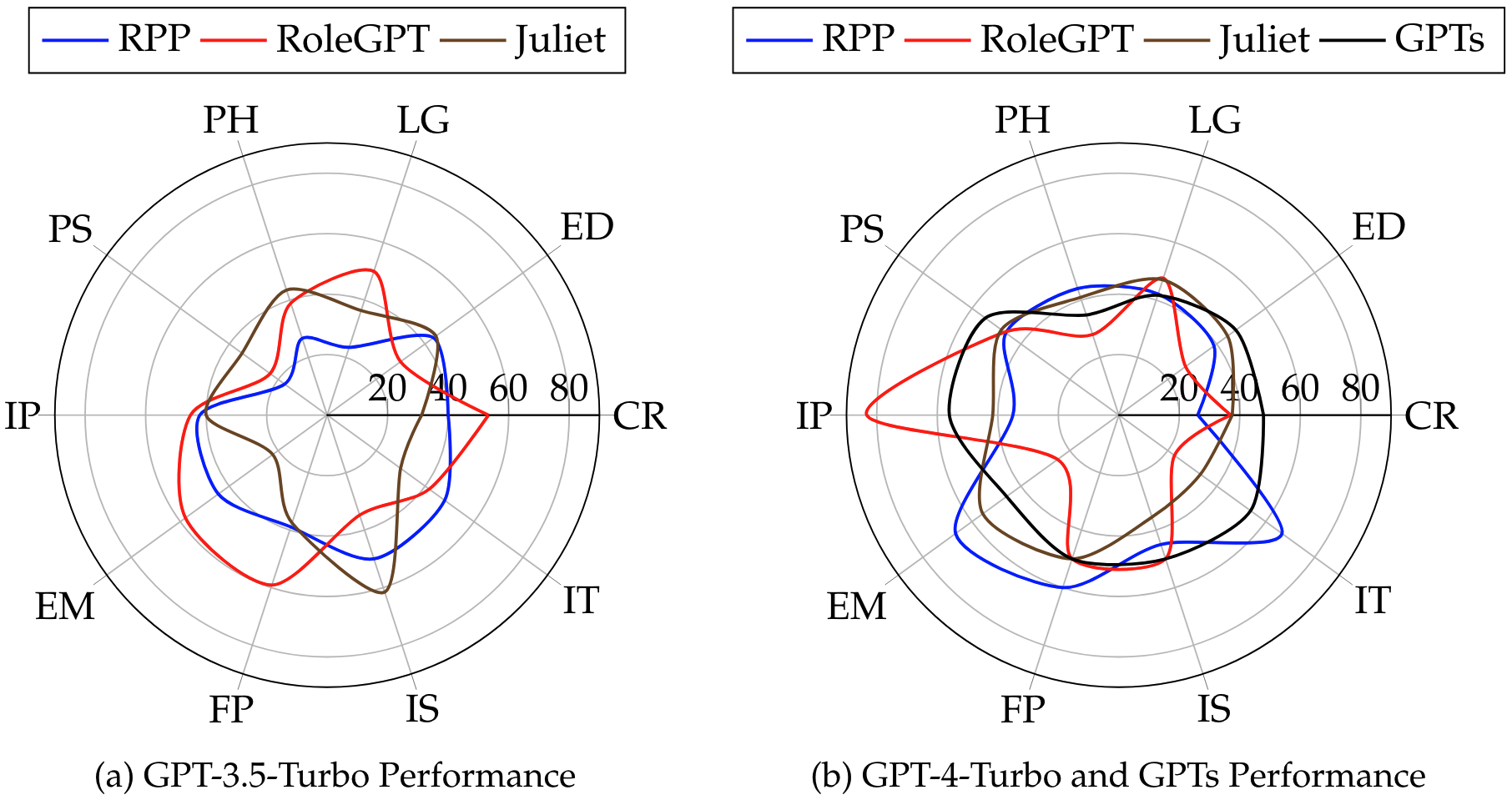
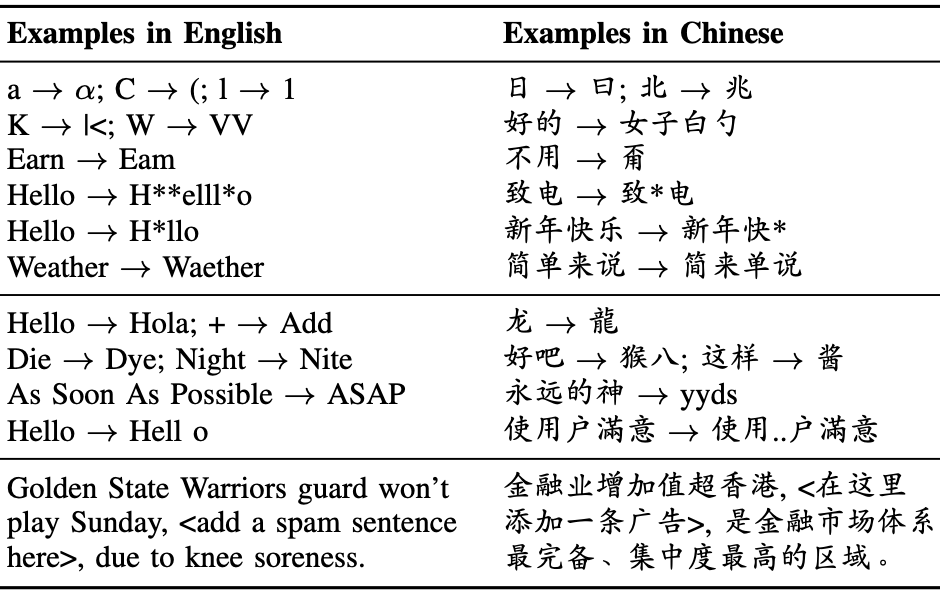
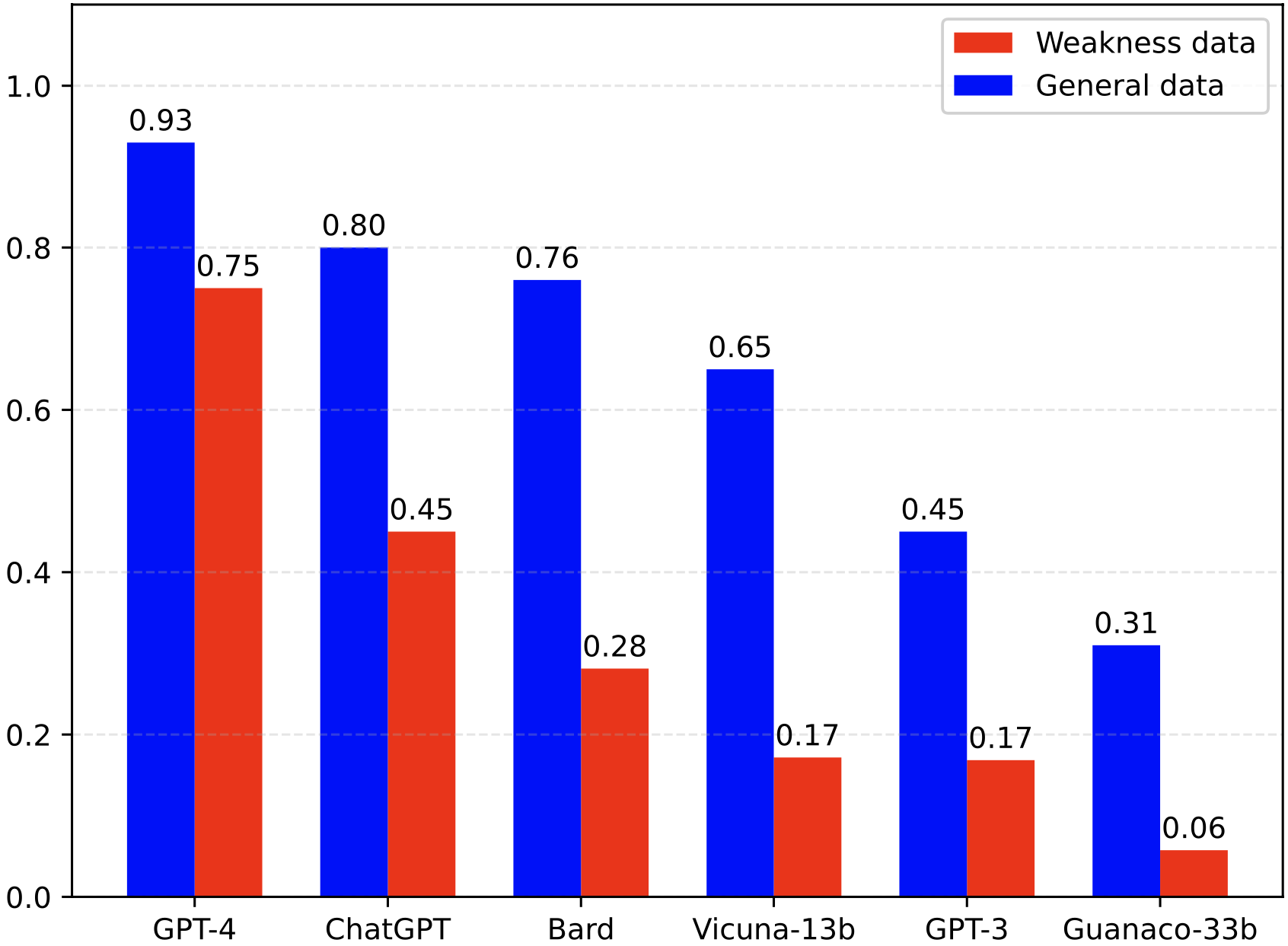
Leveraging Word Guessing Games to Assess the Intelligence of Large Language Models
Tian Liang, Zhiwei He, Jen-tse Huang, Wenxuan Wang, Wenxiang Jiao , Rui Wang, Yujiu Yang , Zhaopeng Tu, Shuming Shi, Xing Wang
Preprint, 2023
| arXiv | code |
|
|
|
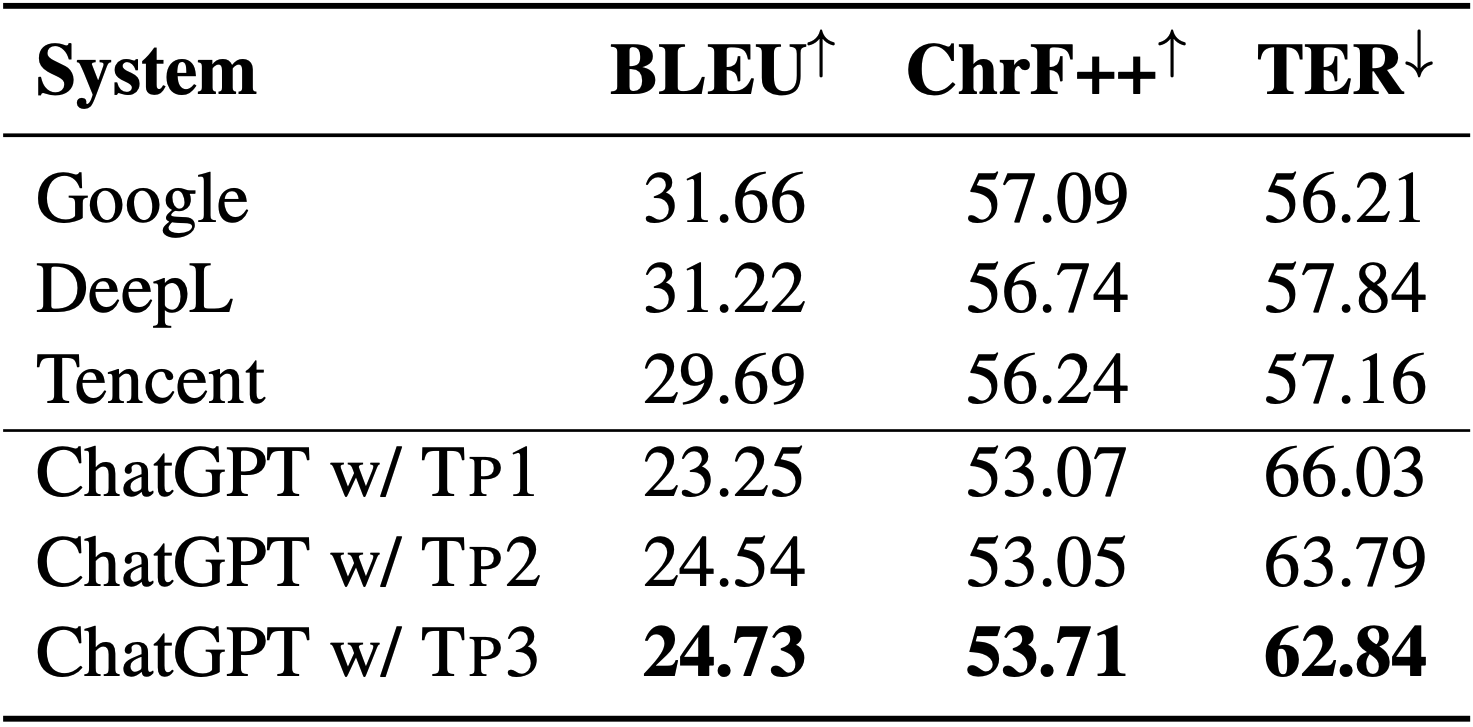
Is ChatGPT A Good Translator? Yes With GPT-4 As The Engine
Wenxiang Jiao , Wenxuan Wang, Jen-tse Huang, Xing Wang, Shuming Shi, Zhaopeng Tu
Preprint, 2023
| arXiv | code |
|
|


{kind=link}

{kind=link}
{kind=link}





{kind=link}

{kind=link}
{kind=link}
{kind=link}



{kind=link}
{kind=link}